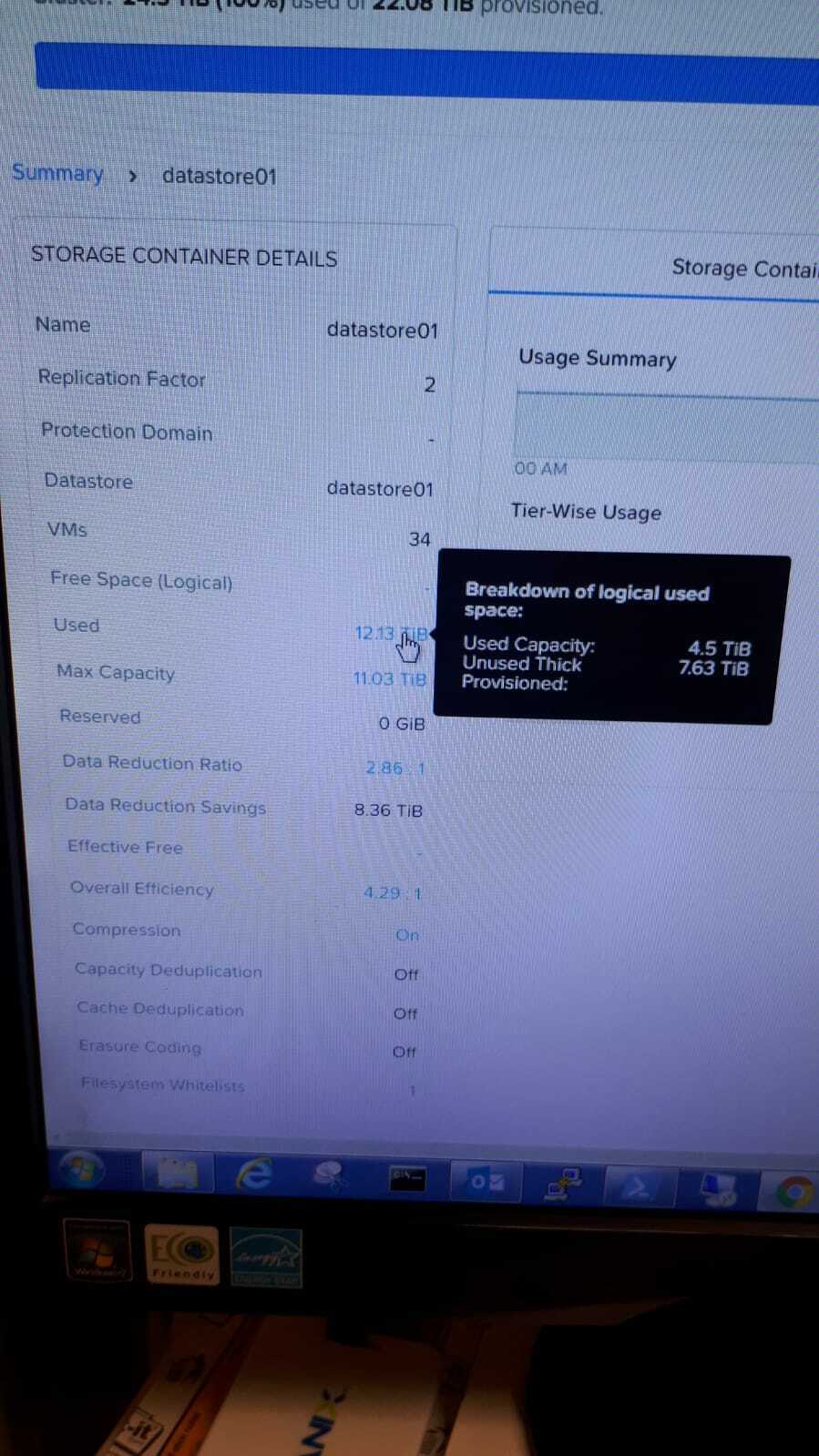
we are performing a POC and we have a cluster that originallly had about 30 Tib of available space made of SSD+ HDD. Then, to show the customer the performance improvement moving to All Flash we made an inline conversion addind SSD and removing all the HDD and now we have a total available space is about 11 TiB.
The storage container has compression enable and the real used capacity is 4,5 Tib.
The problem is that most of the VM are thick provisioned and the actual use space is reported at 12 Tib hence above the available capacity. This triggers RED alarms on the Prism console saying that he Data Resiliency is not available.
So I have 2 questions:
1) since the actual used capacity is 4,5 Tib what happens in case of a disk failure?
2) how can we manage to eliminate these alarms?
Question number 2) is particularly relevant since if we succeed in the POC and the customer could purchase Nutanix all flash systems , they will like to use them without changing their policies and exploitining the data reduction functionalities of Nutanix.
.
Today they have many VMware cluster with Pure Storage systems that use LUNs compressed and deduped in the background without "complaining" about thick provisioning...
Thanks in advance for any suggestion.
Stefano