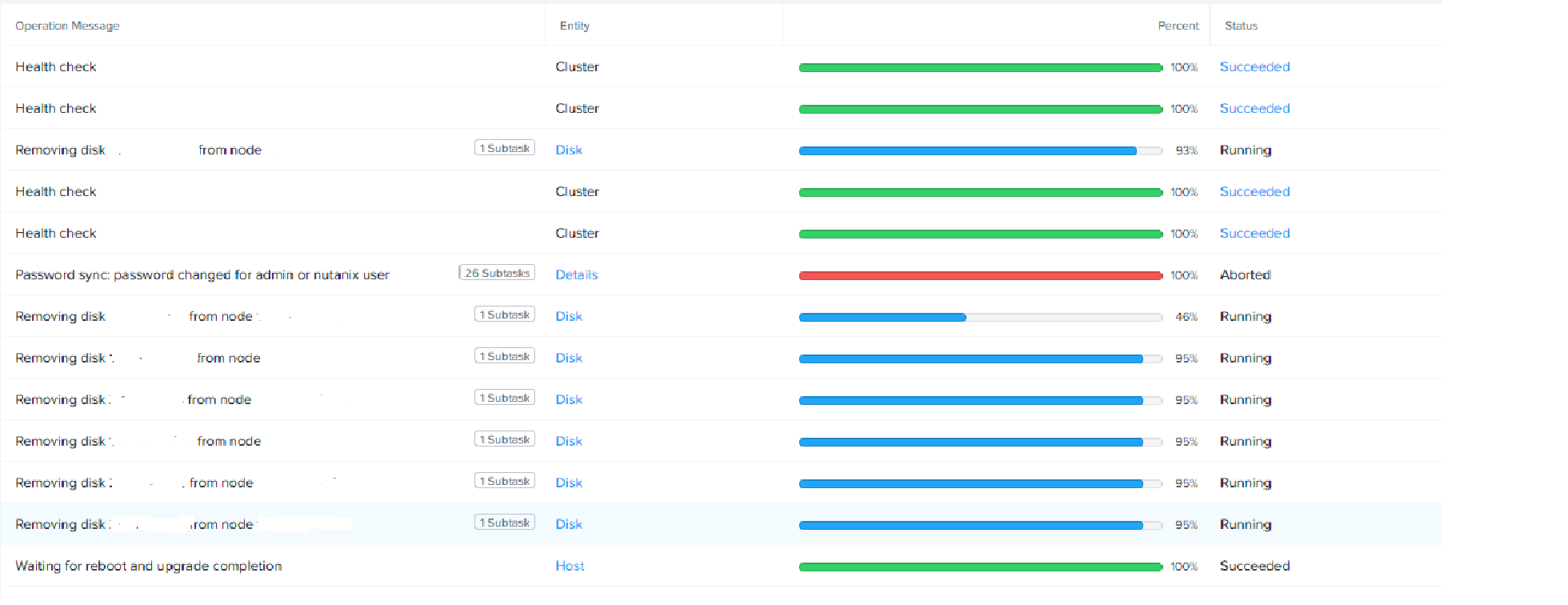
I have a 20+node cluster and 2 nodes had multiple hard drives go out between them ( 1 SSD and 6 SATA). They are all showing stuck. I do not see any replication happening when using this command:
curator_cli get_under_replication_info summary=true.
All nodes show up good when using this command:
nodetool -h 0 ring | grep Normal
Would it be a good idea to kill the tasks with this command:
cvm$ progress_monitor_cli --entity_id="<Entity_ID>" --entity_type=<Package_Name> --operation=<Operation -delete