

Beside the “classical” Monitoring with snmp or agent based version now we are talking about Metrics and the Monitorng of LiveData with the OpenSource Project Prometheus. The Virtualization is made with the powerfull Tool of Grafana.
The access to the Data will be made with so called “Node-Exporter” which could we found under GitHUB. One is present for Nutanix!
My Testcase in the homelab is build with the following items:
NutanixCluster <- Prometheus <- Grafana
192.168.10.80 192.168.10.123 192.168.10.100
Nutanix CE Ubuntu 18.04 LTS Ubuntu 18.04 LTS
Prometheus 2.2.1 Grafana 7.0.4
GO 1.10
Requirements
- Create NEW User in Nutanix Prism Central with VIEWER Rights

2. Installation of Prometheus on Ubuntu 18.04 LTS with running GO!
Good Sourcse will be available here or here.
3. Installation ofvon Grafana 7.x on a second Ubuntun 18.04 LTS
Good Source are found here.
Start of Connection to Nutanix
- We download the GO Binary for the Nutanix Exporter to the Prometheus VM in the folder of GO/BIN
We will test the go/bin share with the --help command:
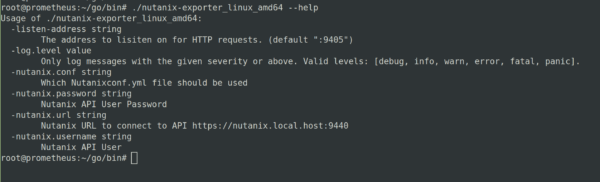
SO is should be. No we try to check if our new created VIEWER User is able to feth some metrics from the nutanix cluster. If we describe no seperate port Prometheus is using port 9405. If you are connection to more then one cluster you have to describe for each cluster a seperate port!

You could connect via IP or create an DNS Entry for it. Username/Password could be masked in variables if needed!
The Result on Port :9494 on our Prometheus Server is as follows:
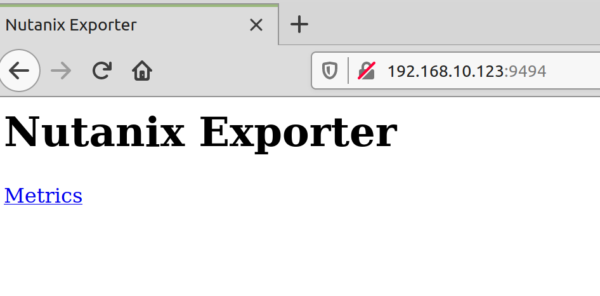
BINGO. With a click on Metric you get all Metrics which are available...
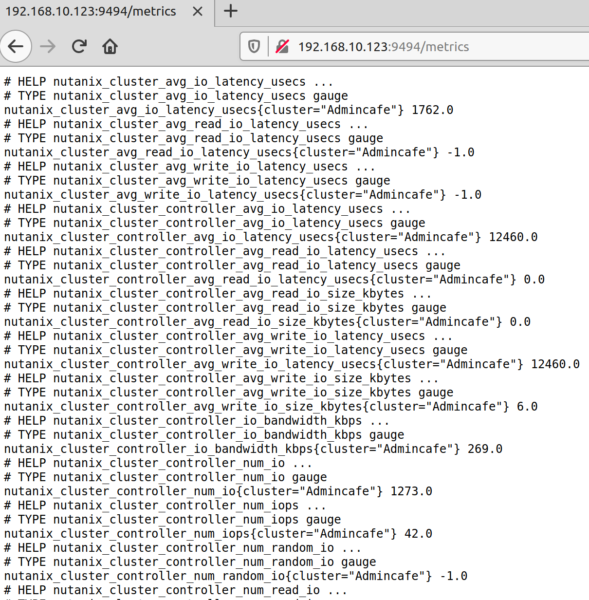
THIS was the manuell way.
Now we build a little shell script which is doing these call automatically. We also create a Service on the prometheus server to be reboot aware!
We create the Shell Script in /etc/systemd/system as a new SERVICE!
- Bash-Script will be created in the share of /go/bin (Example Code)

2. Creation of a new Service in /etc/systemd/system
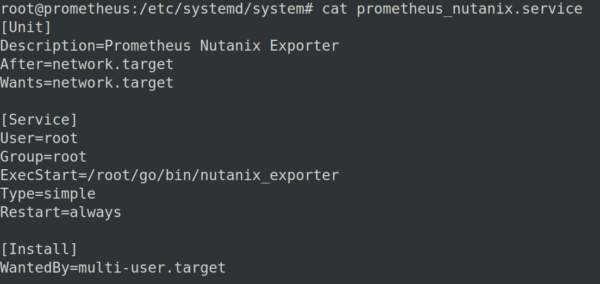
Enable the service with “systemctl enable prometheus_nutanix.service”
We reboot the VM and check if all is fine and running automatically now:
systemctl status prometheus_nutanix.service

We will find the Metrics now on the give :port on the Prometheus. But for the work with Grafana the Exporter needs to be declared as a TARGET !
Modify /etc/prometheus/prometheus.yml and put in the following section! Restart the Prometheus Service!

Controll the default Prometheus on Port :9090 if the new created TARGET is present and working.
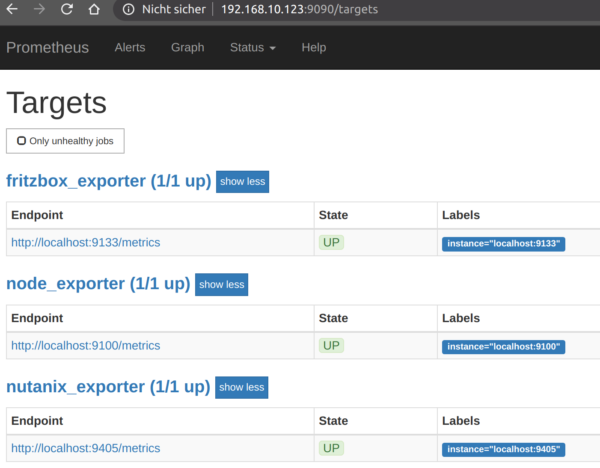
Fine! Now we switch over to GRAFANA
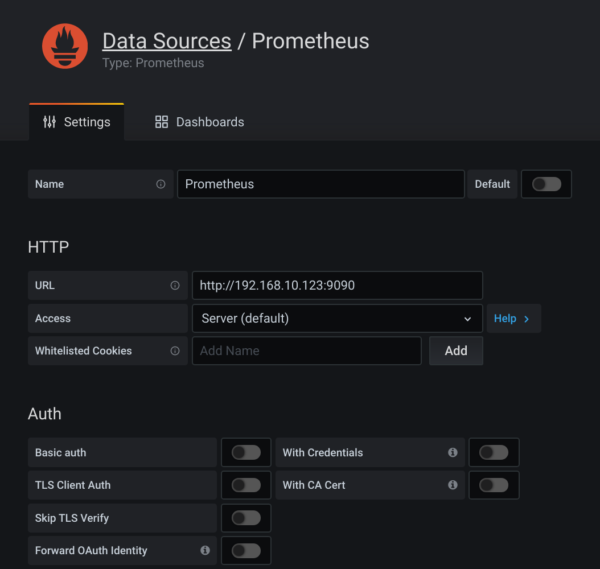
- We declare Prometheus as a new Datasource in Grafana
Now we created a new Dashboard and select METRICS under Prometheus/Nutanix.(btw. Exportername from the Prometheus Config)
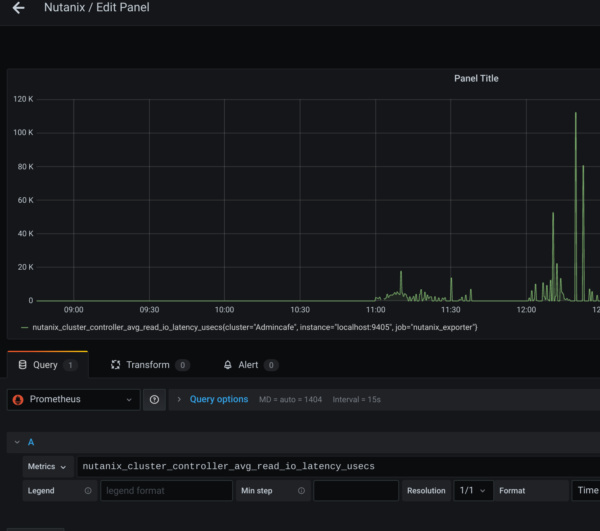
Attention! It makes sence to declare EACH Cluster with a valid NAME in the Prometheus Config!
I created just a simple Example Dashboard with VM Account, Memory etc.
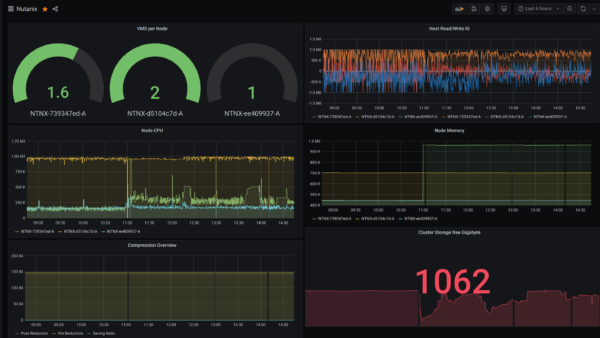
If you like to start with that just download the JSON File from my Github Repo here and import it as a new Dashboard.
Handling Tips:
Export all Metrics from the Prometheus Metrics Site to Notepad++ / Sublime for easy searching!

The Values behind HELP and TYPE are irrelevant. But the NAME of the Metrik is key! Copy and Paste it from here to the selection in Grafana!
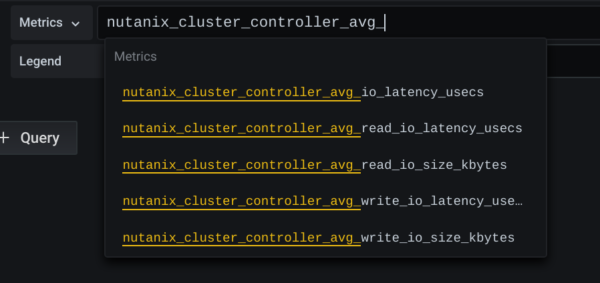
The LEGENDS show in default the NAME of the Metric. But you could
a) manuell overwrite it
b) Use Variable like {{cluster}} or {{node}}
- Convert BYTES via /1024/1024/1024 etc. in MB/GB/TB

Have Fun with your Dashboards…….