


本記事は2018年5月30日にJosh Odgers氏が投稿した記事の日本語版です。
2013年半ばからNutanixに勤務し、ビジネスクリティカルなアプリケーション、スケーラビリティ、回復力、パフォーマンスに注力してきました。私はお客様やパートナーと、回復力について、また、Nutanixプラットフォームをどのように構成するのがベストなのかについて、たくさんの議論をしています。
Nutanixプラットフォームの多くの強みの1つであり、私が多くの時間とエネルギーを費やしている分野は、回復力とデータの整合性です。それには障害のシナリオとプラットフォームがどのように対処するかを理解することが重要です。
Nutanixは、独自の分散ストレージファブリック(ADSF)を使用して、仮想マシン、コンテナ、さらには物理サーバーにストレージを提供しています。このストレージは、レジリエンシーファクター(RF)2または3で構成することができます。つまり、回復力とパフォーマンスのために、データは2つもしくは3つのコピーが保存されます。
単純化して考えれば、RF2とN+1(例:RAID5)、RF3とN+2(例:RAID3)を比較するのは簡単です。しかし、実際には、RF2と3は分散ストレージファブリックのおかげで、従来のRAIDよりもはるかに高い耐障害性を持っています。これは、障害からのリビルドを極めて迅速に行うことができることと、障害が発生する前に問題を検出して解決するプロアクティブなディスクスクラビング機能を備えているためです。
Nutanixは、読み取りと書き込みのたびにチェックサムを実行し、データの整合性を最大限に確保するための継続的なバックグラウンドスクラビングを行います。これにより、LSE(Latent Sector Errors)やビットロット(Bit Rot)、通常のドライブの消耗などが事前に検出され、対処されるようになります。
ADSFの回復力を議論する際に重要なのは、ドライブやノードに障害が発生した場合に、RF2またはRF3に準拠した状態まで回復する速度です。
リビルドは、すべてのノードとドライブにまたがる完全な分散処理(多対多の処理)です。ですから、非常に高速ですし、ボトルネックを回避するため、そして稼働中のワークロードへの影響を軽減するため、ノードごとの作業負荷が最小限に抑えられます。
速いとはどのくらいの速度でしょうか?もちろん、クラスターの規模、ドライブの数や種類(NVMe、SATA-SSD、DAS-SATAなど)、さらにはCPUの世代やネットワークの接続性など、さまざまな要素に左右されます。ですが、それを踏まえた上で、一例を挙げてみましょう。
テスト環境は、Ivy Bridge 2560プロセッサ(2013年第3四半期に販売開始)を搭載したNX-6050およびNX-3050ノードなど、約5年前のハードウェアを組み合わせた16ノードのクラスターです。各ノードにはサイズの異なる6つのSATA-SSDと2つの10GBネットワーク接続を搭載しています。
今回のテストでは、データ削減技術(重複排除、圧縮、イレイジャーコーディング)は使用しませんでした。これらの技術は、達成されたデータ削減に応じてリビルドのパフォーマンスを歪めてしまうかもしれないためです。ですから、このテストケースの結果はベストケースのシナリオではありません。データ削減技術によってパフォーマンスが向上し、データ削減率によって再保護が必要なデータ量が減少するからです。
下図のように、(擬似的に障害を起こす)ノードでは5TB強のデータが使用されているので、本日測定する速度は、模擬的なノード障害から5TBをリビルドする際のパフォーマンスになります。クラスター内の半分のノードは約9TBの容量を持ち、残りの半分は3TBから1.4TBの容量を持ちます。
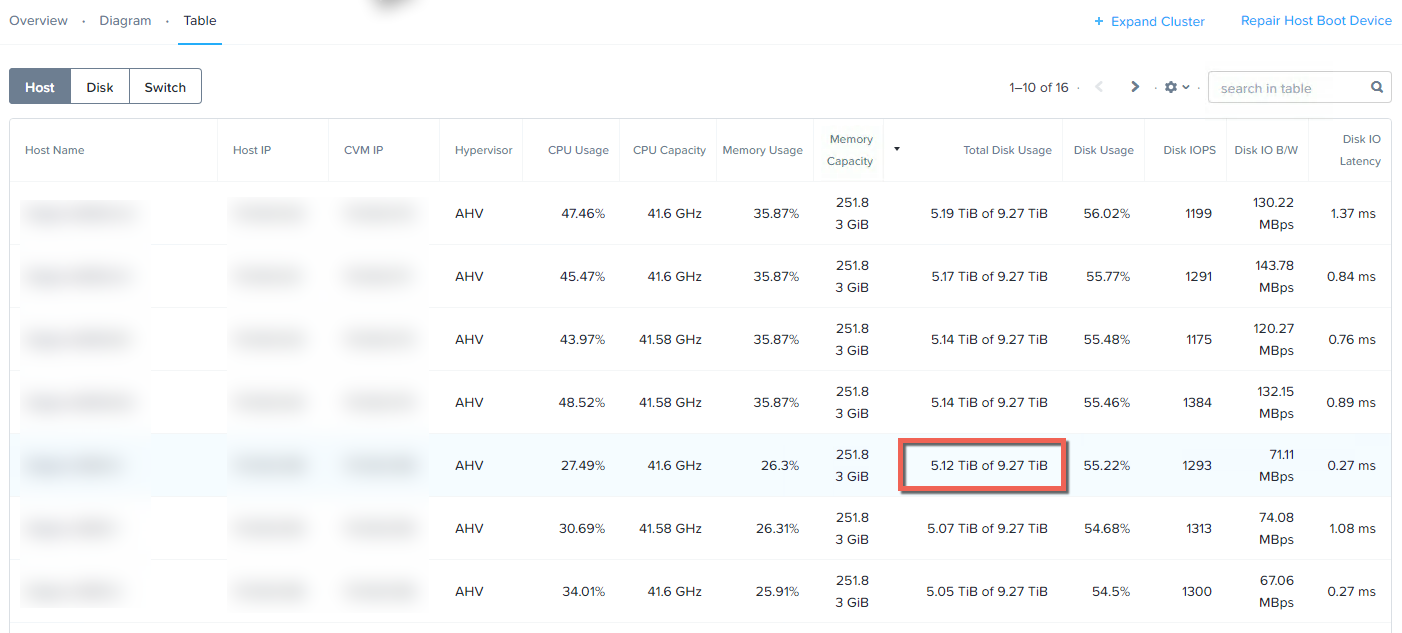
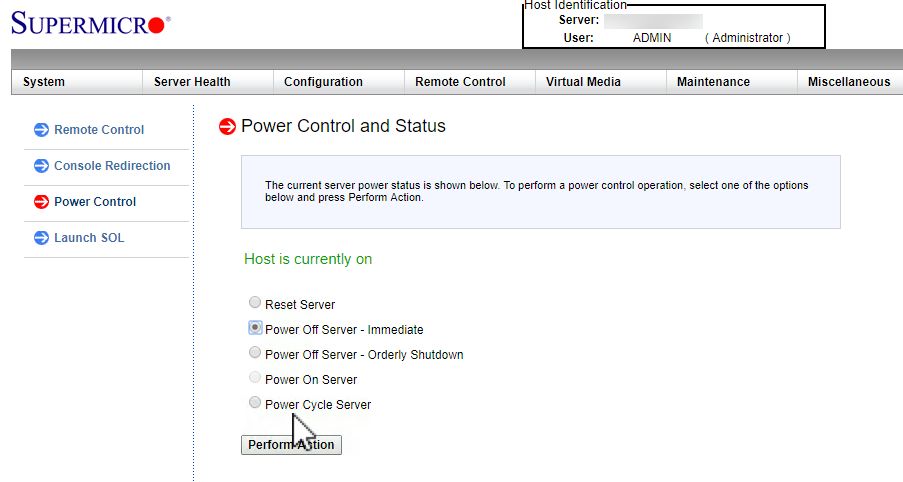
IPMIインターフェースを使用して、下図のように「サーバの電源オフ - 即時」オプションを使用することで、ノード障害をシミュレートします。これは、物理的なサーバーの背面から電源を抜くのと同じことです。
ノード障害時のノード毎の統計情報を見れば、Acropolis Distributed Storage Fabric (ADSF)の回復力の優位性は明らかです。1台のノードあたり1GBpsをはるかに超えるスループットが観測できます。クラスタ内のすべてのノードがその容量に応じてほぼ同等のスループットを提供していることがわかります。
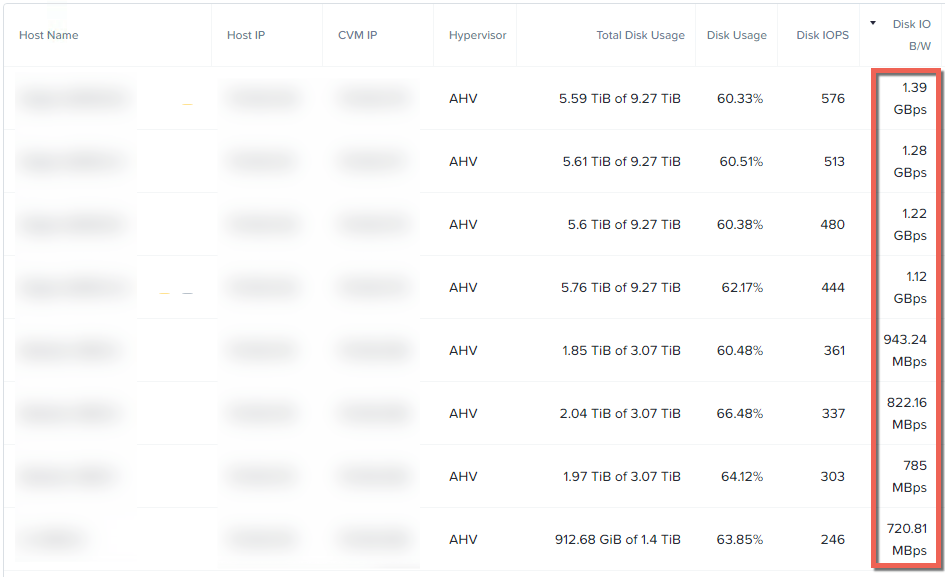
半分のノードのスループットが低い理由は、それらのノードの容量が非常に小さいため、リビルドに提供できるデータ(レプリカ)が少ないためです。すべてのノードの容量が同じであれば、リストの最初の4つのノードが示すように、スループットはほぼ均等になります。
Nutanixが分散ストレージファブリックを持っていない場合、リビルドは、RAIDやより初歩的なHCIプラットフォームのように、ソースおよびデスティネーションノードによって制約されるでしょう。例えば、初歩的なHCIプラットフォームではノードAが大きなオブジェクトをノードBにレプリケートするのに対して、Nutanixでは、すべてのノードが小さなエクステント(1MB)をクラスタ全体にレプリケートしており、効率的な多対多のプロセスでおこなわれます。
従来のRAID5と比較してみましょう。RAID5の場合、リビルドのソースになるのは障害が発生した特定のRAID内のドライブのみになります。RAIDセットは一般的に3から上限の24まであり、リビルド先は1台の「ホットスペア」または交換用ドライブになります。つまりリビルド作業は、1台のドライブがボトルネックになるのです。
ほとんどのITの専門家は、RAID 5やRAID 6が1台のドライブの故障から復旧するのに長時間(通常は数時間から数日)かかったために、リビルド中の故障でデータを失ったという経験をしているでしょう。1台のドライブを故障から復旧するために、RAIDグループ全体の再構成が必要になるのです。
RAIDグループ内のドライブ数が多いほど、リビルドに時間がかかり、その後の故障によるデータ損失のリスクが高くなります。RAIDリビルド時のパフォーマンスへの影響は、ソースとなるドライブのサブセットとデスティネーションとなるドライブが通常1台しかないため、非常に大きくなります。つまり、パフォーマンスに影響を与える時間が長くなり、データが保護されなくなるのです。
このようなよくある失敗の経験が、N+1(さらにはRF2)が悪い評判を受けている主な理由だと私は考えています。もしRAID 5や6がドライブ障害から数分でリビルドできるなら、続いて起こった障害の大部分はダウンタイムやデータ損失に至らなかったでしょう。
さて、Nutanix ADSFのリビルドのパフォーマンスに話を戻します。
繰り返しになりますが、ADSFはレプリカ(データ)を1MB単位でクラスタ全体に分散するため(すべてのデータが2つのノードにしかない「ペア」スタイルの構成とは異なります)、プラットフォームは書き込みパフォーマンスを向上させることができます(より多くのコントローラがI/Oを処理するため)。また、リビルド時には、より多くのコントローラ、CPU、ネットワーク帯域がリビルドの処理に利用できます。
つまり、クラスターが大きければ大きいほど、レプリカを読み書きするノードの数が増え、リカバリーを高速に実行できるようになります。障害発生時やリビルド時の影響は、クラスターが大きいほど小さくなります。つまり、大規模なクラスターであれば、RF2を使用しても優れた回復力が得られるということです。
以下は、Nutanix PRISMのHTML 5 GUIのAnalysisタブのスクリーンショットです。これは、擬似的なノード障害からのリビルド中のストレージプールのスループットを示しています。
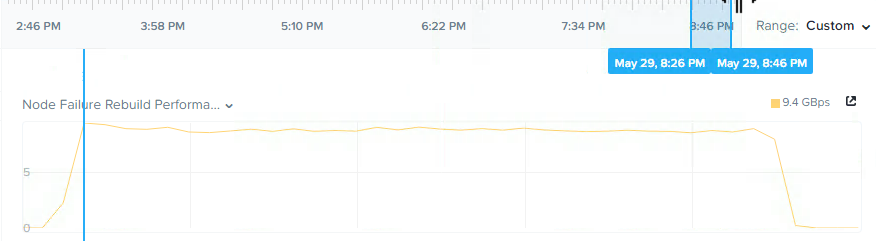
ご覧のとおり、チャートでは、リビルドは8.26PM以降に開始され、8:46PM以前に完了し、完了まで約9GBpsのスループットを維持しています。
つまり、この例では、5TB以上の容量を使用している5年前のノードの場合でも、20分以内にデータの完全な整合性が復元されています。
クラスターのサイズがさらに大きくなったり、より高速なプロセッサやNIC、NVMeドライブなどのストレージを搭載した新しいタイプのノードを使用した場合は、リビルドが大幅に高速化されるかもしれません。しかし、この例の場合でも、RF2(データの2コピー)を使用した場合に、連続した障害によってデータが失われるリスクは非常に短い範囲に限られることがわかります。
まとめ
- Nutanix RF2は、RAID5(またはN+1)スタイルのアーキテクチャと比較して、圧倒的に回復力に優れています。
- ADSFは継続的にディスクスクラビングを行い、データの整合性の問題が発生する前に根本的な問題を検出し解決します。
- ドライブやノードの障害からのリビルドは、クラスタ内のすべてのドライブとノードを使用した効率的な分散処理です。
- 5TB以上のノード障害(このケースでは、6台のSSDが同時に故障した場合に相当)からのリカバリは、20分以内に完了します。
次回は、RF2からRF3への変換方法と、新たなポリシーに準拠するためのタスクをいかに早く完了できるかについて説明します