


本記事はRaghav Tulshibagwale氏が 2021年3月10日に投稿した記事の翻訳版です。
原文はこちら。

本日の記事では、また新たなゲストライターを紹介させていただきます。皆さん、Nutanixのスタッフエンジニア、Raghav Tulshibagwaleにご挨拶を!本日の記事では、継続的なシリーズの第1弾として、Raghavが私たちをNutanixにおけるRocksDBの旅へと案内してくれます。そしてRocksDBがNutanixプラットフォームアーキテクチャの様々な側面にどのように適用されているのかをご紹介します。
私がRaghav自身よりもうまく説明することは到底できませんので、さっそく始めましょう!
はじめに
2016年初めのアーキテクチャ検討会以来、Nutanixエンジニアチームは、分散ストレージファブリックの3つの大きな目標、すなわち、持続的でランダムな書き込み性能の向上、大容量ディープストレージノードのサポートの追加、バックグラウンドでのデータ管理の効率化に取り組んできました。
これらの目標を明確にし、詳細を詰めていくうちに、私たちの限界要因はアーキテクチャ自体にあることに気づきました。さらに改善し、将来のスケーラビリティ(拡張性)のニーズに対応するには、Nutanixでのメタデータの保存方法を完全に再構築する必要がありました。
メタデータをデータに近づけるという私たちの最大の目的には、メタデータを保存するための新しい基盤コンポーネントが必要でした。
すでにうまく機能しているシステムに、まったく新しいコンポーネントを導入するのは、リスクの高い試みです。最終的にオープンソースのキーバリューストア(KVS)であるRocksDBを選択しましたが、これはあらゆる選択肢を調査し、それぞれの潜在的なコストと効果を考慮した結果です。オープンソースのソリューションが、十分な信頼性と耐久性を持ち、私たちのチームが数カ月で十分なノウハウを身につけ、そのコンポーネントを本当に自分たちのものにできるのかを確かめたかったのです。
このブログシリーズの最初の記事では、専門用語、自律エクステントストア(AES)プロジェクトの全体要件、新しいコンポーネントの選択基準、エクステントストア用のRocksDB展開の概要、現在RocksDBを使用している他のNutanix製品およびコンポーネントを簡単に紹介します。続いて、RocksDBに関するこれまでの課題、成功、教訓を振り返り、特定のユースケースをより詳細に説明します。
主なNutanix用語
詳細に入る前に、議論の過程で使用されるNutanix用語のいくつかを定義しておきましょう。
エクステントストアとは、ディスク上にホストされているエクステントという単位でユーザーデータを管理する永続的なNutanixデータストレージのサブシステムです。エクステントストアは、そのほかにも、データ変換やマイグレーションのような処理も行います。
メタデータストアは、分散永続ストレージ層であり、エクステントストアが保存するすべてのユーザーデータのメタデータを管理します。メタデータストアは、クラスタ全体のプロパティの情報を提供するグローバル状態と、(特定のホスト上のディスクに限定される、その)ディスク上のデータレイアウトに関する情報を提供するローカルメタデータの、2つの状態を維持します。Nutanixメタデータストアは、オープンソースのCassandraに多くの手を加えたもので、強力な一貫性とデータの耐久性を保証しています。内部的には、手を加えたPaxosコンセンサス・アルゴリズムを使用して、分散環境でのサービスを実現しています。内部については、NSDI Metadata Store Paperで詳しく説明されています。
Nutanixの分散ストレージファブリックのバックグラウンドデータ管理システム(BDM)は、ガベージコレクション、データ変換ポリシー、データ重複排除、階層化のためのデータ移動などの動作を担います。BDMは、MapReduceフレームワークに手を入れて、これらのインテリジェントな決定を行うために使用しています。内部の詳細については、NSDI Curator Paperでご覧いただけます。
必要条件
持続的なランダム書き込み性能の向上
広く利用されている電子カルテのプラットフォームを支えるデータベースの性能向上のリクエストについて取り組んでいるとき、高い書き込み増幅(ライト/アンプリフィケーション)とI/Oパス内でメタデータストアが大きく関与しているために、エクステントストアが望ましい持続的なランダムな書き込みについての性能を実現できていないことがわかりました。メタデータストアはそれ自体が高度に分散したもう一つのサービスであるため、Paxosプロトコルのもとで、トランザクションを完了するために、I/Oは複数のホストを経由(ホップ)しなければなりません。I/Oストアのサービス飛び出して、空き領域を探し出し、ネットワークを横断する間に、Paxosコンセンサスプロトコルの複雑さが、ユーザーデータの書き込みI/Oパス全体に影響を与え始めました。 持続的なランダム書き込み性能の大幅な改善は、最優先の要件となりました。
ディープストレージノードのサポートを実装
スピンドル(磁気ディスク)の低価格化とそれに伴う大容量化に伴い、オブジェクトストレージ、長期保存サービス、バックアップなどのユースケースに対応したディープストレージノードのサポートが重要な優先課題となっていました。 私たちの目標は、1ノードあたり少なくとも300TBをサポートすることでした。
バックグランドのデータ管理のコスト削減
バックグラウンドデータ管理システム(BDM)は、メタデータストアを使用して、メタデータの読み取りとスキャンニングにより意思決定を行います。BDMはMapReduceフレームワークの一部としてメタデータストアのグローバルスキャンを実行しますが、このスキャンはクラスタサイズが大きくなるにつれて非常にコストのかかる処理となります。グローバルデデュプリケーション(重複排除)は、その対価としてコストが伴います。メタデータストアが必要とするパターン抽出とマッチング処理をサポートするために、メタデータストアはかなり多くのメタデータを保持しなければならないからです。全体として、様々なユースケースをサポートするための”グローバル”メタデータ管理のコストは増加していました。このコストに対処するために、私たちはBDMのすべての動作(データ階層化、重複排除など)の背後にある根本的な部分を変えたいと考えていました。
以下のような要件を整理していくと、エクステントストアのアーキテクチャを根本から変える必要があることが次第に明らかになってきました。
新たなエクステントストアアーキテクチャ
「メタデータをデータに近づける」というのが、既存のエクステントストアを再設計する際の基本原則となりました。つまり、エクステントストアを自律化し、グローバルな分散メタデータを参照するのではなく、ローカルのメタデータを使用してローカルなデータについて意思決定できるようにするのです。この変更により、個々のノードがエクステントストアのデータ更新を保持し、ローカルでバックグラウンドのデータ管理を提供できるようになります。そのため、メタデータストアにある物理レイアウトメタデータをエクステントストアへより近づける必要がありました。
そのためには、メタデータストアからすべての物理データレイアウトメタデータ(ローカルステート)を移動できる、ホスト上にローカルに展開できるデータベースまたはKVSが必要でした。ディスクのサイズが大きくなっていくことを考えると、各ディスクは自身のデータ(エクステント)とそのデータのメタデータ(エクステントレイアウト情報)を扱うことができる自律的なストレージシステムとなるでしょう。
このローカルメタデータストレージには、新しいシステムが必要でした。私たちは、データベースやKVSの候補として、次のような目標を掲げて研究を始めました。
- エクステントストアサービスと同じアドレス空間に属するべき
- データおよびメタデータの同居管理が可能であること
- ネットワークホップが不要であること
- Writeに最適化されたバックエンドで、かつ、Read性能が許容範囲内であること
- データベースの軽量なACID(不可分性、一貫性、独立性、永続性)の特性をサポートすること
- エクステントストアサービスがC++で記述されているため、C++で実装されていること
- メタデータストアがCassandraをベースにしているため、Cassandraと同様の外部APIを公開できること
複数の選択肢を検討した結果、Facebookが開発したオープンソースのKVSであるRocksDBが、これらの要件から非常に適していると判断しました。以下のセクションで説明するRocksDBの特性が、私たちの決断を後押ししてくれました。
RocksDB: 組み込み可能なC++ライブラリ
Nutanixのエクステントストアは、全体が高度なC++(C++11/14)で実装されているため、エクステントストアとリンクして同じアドレス空間にKVSをセットアップできる埋め込み可能なライブラリであることが望ましいと考えました。この同居により、プロセスやネットワークホップを回避して、ローカルメタデータの参照が可能となります。RocksDBは、C++ライブラリとして実装されています。
RocksDB: LSMストレージエンジン
先に述べたように、メタデータストアは高度に我々の手が入ったCassandraベースのKVSであり、Nutanixストレージのすべてのメタデータをホストしています。Cassandraと同様に、RocksDBはすべてのデータを管理するためにLSM(log-structured merge)ツリーストレージエンジンを使用します。私たちのLSMアーキテクチャへの精通を考えると、RocksDB KVSは当然の選択となりました。LSMストレージエンジンは書き込みに最適化されており、許容できる読み取りとスキャンのパフォーマンスを提供するため、持続的なランダム書き込みパフォーマンスを向上させるという全体目標をサポートします。
RocksDBは、フラッシュドライブなどの高速で低レイテンシーのストレージにも最適化されています。このエンジンは、フラッシュやRAMが可能にする高い読み取り/書き込み速度のポテンシャルを最大限に引き出します。OptaneやNVMeドライブなどのストレージデバイスの登場により、RocksDBは新しい基盤にふさわしいプラットフォームとなりました。
RocksDB:APIと機能セット
RocksDBは、任意のバイトストリームをキーと値で表すインターフェースを提供します。公開されている基礎的なAPIは、Put、Delete、Get、およびCreateIteratorです。RocksDBは、キーと値のペアをカラムファミリ(リレーショナルデータベース管理システムのテーブルに似ている)に格納します。このデータモデルにはすでに馴染みがあり、エクステントストアも同様のAPIを使用してメタデータストアとやり取りしています。
Nutanix AOSはエンタープライズグレードの製品であるため、ログベースのライトアヘッド(先行した書き込み)の永続性とデータチェックサムのサポートが重要でした。RocksDBは、WriteBatch(バッチ書き込み)のサポートやMVCC(Multi Version Currency Control)に似たセマンティクスを持つスナップショット独立性などの機能を通じてACID特性をサポートしており、これは魅力的でした。さまざまなデータ圧縮アルゴリズム、多様なマルチスレッドガベージコレクション戦略(コンパクション戦略)、調整可能なキャッシュメカニズム、調整可能なデータ保存時のインデックスメカニズムのサポートは、完全なサブシステムたりうる証を示しました。
RocksDBの最も本質的で重要な機能の1つは、Envと呼ばれるプラグイン可能な永続層バックエンドです。Envは、実装がEnvインターフェースに準拠していれば、どんなバックエンド上でもRocksDBを展開することができるのです。この柔軟性により、EXT4やNutanixブロックストアファイルシステムなどのローカルファイルシステムバックエンド、さらにはS3などのクラウドストレージバックエンドにもRocksDBを展開することが可能になるのです。これらの機能の詳細については、RocksDB Wikiをご参照ください。
RocksDB: オープンソース
Facebookは、Googleのプロジェクトとして始まったLevelDBを利用してRocksDBを開発しました。RocksDBは、Facebook社のさまざまなユースケースで実稼働していましたが、彼らはこれを惜しみなく完全にオープンソース化してくれました。RocksDBのオープンソースコミュニティは活発で、Uber、Airbnb、Netflixなどの組織から支持されており、RocksDBを使うことへの自信をさらに深めることができました。
エクステントストアのためのRocksDB展開
メタデータをデータに近づけるために、メタデータストアの設計を見直し、ローカルステートメタデータを元の分散メタデータストアからエクステントストア内に移動させました。
各データベースがRocksDBインスタンスである、複数の組み込みデータベース・モデルを使用しました。I/Oストアサービスのコンポーネントの1つであるエクステントストアは、そのノードやマシンがホストしているすべてのデータディスクを管理します。このモードでは(次の図を参照)、各ディスクは同じディスクにバックアップされたRocksDBインスタンスでそのローカルメタデータを保持します。
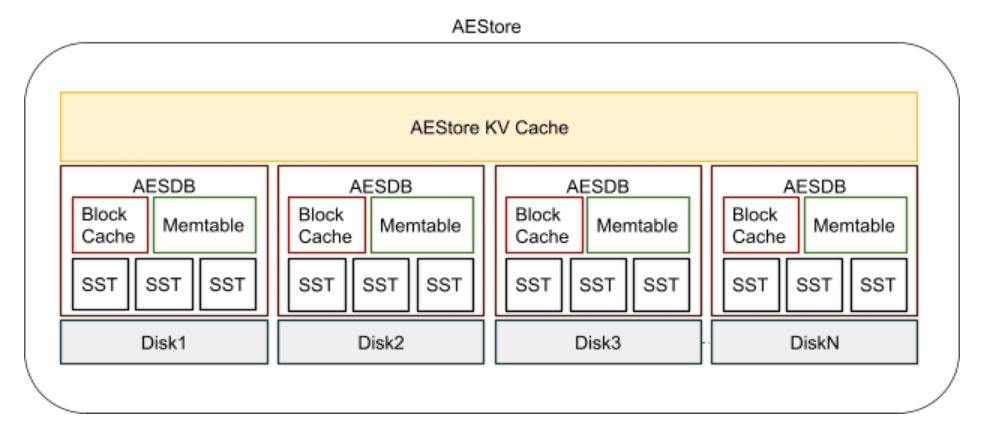
この新しく再設計されたエクステントストアは、自己保有データと物理レイアウトメタデータの両方を管理するため、自律型エクステントストア(AES)と呼んでいます。各RocksDBインスタンスは、それがホストされているディスク上のデータのメタデータを保持する自律エクステントストアデータベース(AESDB)です。
基本セットアップ
下から順に、新しいエクステントストアアーキテクチャは、データおよびメタデータのブロックサイズが4KBのブロックベースのSSTable(sorted static tableまたはsorted string table)を使用しています。データブロックレベルでチェックサム機能を有効にし、圧縮はAESの最初のバージョンでは無効にしています。SSTableメタデータでは、効率的なポイント検索のために10ビットのブルームフィルターを利用して2つのレベルパーティションインデックスを使用しています。SSTableに20個と36個に制限を設け、それぞれで書き込みが抑制、停止されるようにしています。最大3つのスキップリストベースのmemtablesを使用しています。それぞれの最大サイズは標準の設定では64MBです。各AESDBインスタンスは、現時点では、他のインスタンス間とは共有されない独自のブロックキャッシュを管理します。ブロックキャッシュは、メタデータブロック(インデックスと、SSTableからのブルームフィルターブロック)のみをキャッシュします。すべてのAESDBの上で別のAESDBキーバリューキャッシュを保持しているため、データブロックに対してはブロックキャッシュは使用しません。AES KVキャッシュは、論理的に関連するキーと値のペアのグループを単一エンティティとして、まとめて保持します。各AESDBは、カラムファミリを公開し、エクステントストアのメタデータをキーバリュー形式でmemtablesまたはSSTablesへ格納します。エクステントストアは、AESDBに書き込まれたデータの耐久性を保証する独自の独立したWALを維持するため、RocksDBのWALはほとんど使用しません。エクステントストアの既存のWALを利用しているのは、長年に渡って気づいてきたその信頼性と、強い親和性があるからです。
コンパクション
RocksDBには、標準の戦略としてレベルド(階層的)コンパクションが搭載されています。Nutanixでは、当初からメタデータストアにユニバーサルコンパクションを使用しており、それに対して強い親和性があります。したがって、AESの最初のバージョンでは、ユニバーサルコンパクション戦略と単一レベル(階層)を維持することにしました。
スレッディングモデル
各 AESDB は、フラッシュとコンパクションの動作のために独立分離したスレッドを維持します。この分離により、各AESDBインスタンスは、バックグラウンドでガベージコレクションを実行しながら、memtablesからSSTableへのデータフラッシュを単独で進めることができるようになります。
RocksDBの読み込みと書き込みのAPIは同期APIです。つまり、RocksDB上でI/Oオペレーションを実行するスレッドは、操作が完了するまで停止しています。内部的には、RocksDBはリソースの取得時や、ディスクのような永続的な媒体へのI/Oオペレーション操作実行時にスレッドをブロックすることができます。ワーカースレッドがブロックされると、システム全体のスループットが低下するため、この動作はエクステントストアのパフォーマンスに直接影響を及ぼします。この問題を軽減するために、RocksDB I/Oのスレッドモデルを作り直す必要がありました。この特定の問題と私たちの解決策は、次の記事で紹介します。
NutanixでのRocksDB使用例
AESへのRocksDBの導入により、RocksDBが多くのユースケース、特に様々な製品のメタデータを扱う必要がある場合に、基盤となるコンポーネントになることが明らかになりました。次のセクションでは、NutanixにおけるRocksDBの現在のユースケースをレビューします。そして続く投稿の中では、これらのトピックをより詳しく解説していきます。
Nutanix分散型ストレージ
これまで述べてきたように、AESはRocksDBをマルチインスタンス組み込みモードで導入した最初のユースケースでした。現在、AESはオールフラッシュまたはオールハイスピードのパーシステントミディアムクラスタにのみ導入されています。私たちが取り組んでいる次の課題は、高速ディスクと低速ディスクの両方を含むハイブリッド構成でRocksDBを使ったAESをサポートすることです。
ChakrDB: RocksDBで構築した分散型KVS
今後登場する多くのアプリケーションや製品では、規模や性能の要件に準拠した高可用性かつ分散型のKVSが必要ですが、キーバリューライブラリであるRocksDBは単体では提供しません。そのため、複数のRocksDBインスタンス上に分散レイヤーを構築し、スタンドアロンのマルチノードクラスターシステムを構築する必要があることが明らかです。アーキテクチャ的にはCassandraのリングデザインに似ていることから、ChakrDBと名付けました(サンスクリット語でChakrは車輪、輪、円形という意味です)。つまり、ChakrDBは複数のRocksDBインスタンスを使って構築された分散KVSです。ChakrDBについては、次回以降のブログ記事で詳しく説明する予定です。
NutanixオブジェクトのメタデータストアとしてのChakrDB
ChakrDBは、当社のS3準拠のオブジェクトストレージ製品であるNutanix Objectsで初めて使用されました。このストアは、分析用に保存された統計情報とともに、Objectsのメタデータを管理しています。
Nutanix Filesの分析機能
NFS準拠のファイルサービスであるNutanix Filesは、RocksDBライブラリを使用して、分析および監査機能用のローカル時系列データを保持します。
まとめ
私たちは、エクステントストアのパフォーマンスを次のレベルに引き上げ、幅広いユースケースに対応するために、ローカルKVSにすることを目標にRocksDBの旅をスタートしました。それ以来、RocksDBは複数のNutanix製品のメタデータを管理する基盤となっています。
AESの開発の初期段階では、RocksDBをそのまま利用しました。開発の道のりで、私たちのニーズに合わせてチューニングし、RocksDBのコアとなる部分を変更しました。RocksDBを使用しての不満や成功から、私たちは多くのことを学び、多くの経験を積んできました。
このブログ記事は、旅の始まりの序章に過ぎません。このシリーズの後続記事で、私たちの経験や教訓を引き続き共有していきます。
謝辞
「子供を育てるには村が必要だ」 - 今回の再構築の取り組みとRocksDBの新しい旅は、Nutanixの多くの同僚たちの絶え間ない努力なしには実現しなかったでしょう。Tabrez Memon、Chinmay Kamat、Pulkit Kapoor、Sandeep Madanala、Yasaswi K、Rituparna Saikia、Ronak Sisodia、Parmpreet Singhに感謝します。
Nutanix のリーダーシップ、Pavan Konka、Anoop Jawahar、Karan Gupta、Rishi Bharadwaj、Manosiz Bhattacharya へ、継続的な指導とサポートに感謝します。
また、このブログを外部で読めるようにするために貴重なフィードバックをくれたJon KohlerとKate Guillemetteに感謝いたします。