


本記事はAnoop Jawahar氏 および Sandeep Madanala氏が 2021年10月4日に投稿した記事の翻訳版です。原文はこちら。

このシリーズのパート 1では、RocksDBをベースに、数十テラバイトから数ペタバイトまでのスケールに対応する分散型の、クラウドネイティブな、高い可用性を備えた、高性能なキーバリューストア(KVS)を新たに実装するに至った経緯について述べてきました。この記事では、ChakrDBの概要とその特徴、アーキテクチャの詳細について説明し、パート 1で提示した要件の達成にどのように役立ったかをまとめます。
概要
ChakrDBは、分散型のNoSQL KVSです。ChakrDBインスタンスは、複数の仮想ノード(vNode)が組み込まれた単一プロセス、コンテナ、ないしはポッドです。各仮想ノード(vNode)は独立したKVSで、クラスタ内のシャードを所有し、すべてのデータをリモートクラウドストレージ(ボリューム、Nutanix仮想ディスク、またはAWSやAzureなどのクラウドによって提供される任意の仮想ディスク)に書き込みます。vNodeはKubernetes(K8s)が展開したext4ファイルシステムベースのボリュームとNutanixの内部ファイルシステムであるBlockStoreのいずれもをサポートしています。BlockStoreは物理ディスクとNutanixの仮想ディスクを含む様々なタイプの基盤ストレージをブロックベースの抽象化によってサポートします。ブロックベースのファイルシステムにより、vNodeはストレージファブリックと直接対話し、iSCSIよりもext4を使用することで余分なオーバーヘッドを回避し、スループットとレイテンシーを約50%向上させることができます。
ChakrDB の主な特徴
完全な自在性と柔軟性
ChakrDBには、仮想ノード(vNode)に基づくシャーディングデザインが採用されています。仮想ノード(vNode)は、高いスループットとテールレイテンシの改善でリニアなスケーラビリティを実現します。各仮想ノード(vNode)はRocksDB上で動作するラッパーであり、それ自体でKVSスタック全体を保有するため独立性が高く、データの移動と配置に柔軟性を提供します。仮想ノード(vNode)ベースの設計により、クラスタは完全に伸縮自在であり、仮想ノード(vNode)に対する操作だけでシームレスに拡張・縮小が可能です。仮想ノード(vNode) はその性質上、ステートレスなエンティティであるため、仮想ノード(vNode) を移動させても同時にストレージをコピーする必要はなく、結果としてほとんどのクラウドストレージはどのホストやポッドからもアクセスすることができます。この適応性により、高速で柔軟な拡張性と耐障害性を実現可能になります。ポッドのCPU とメモリを増やすため、またはフェイルオーバーに対応するために、仮想ノード(vNode)を別のポッドに再作成することができるのです。
軽量さ
ChakrDBは、RocksDBのいくつかのインスタンス上に実装されたライトウェイトなレイヤーで、レプリケーションやコンセンサスアルゴリズムを含まないため、I/Oパスのオーバーヘッドを増加させることはありません。単一仮想ノードでのChakrDBとRocksDBのベンチマークを行った結果、このレイヤーのオーバーヘッドはごくわずかで、ChakrDBのパフォーマンスは改変以前のRocksDBとほぼ同じであることがわかりました。
将来性
ChakrDBは、LSM(Log-Structured Merge)ツリーをベースとしたKVSであるRocksDBをベースに設計されています。LSMデータ構造はSSDに最適化されており、NVMeデバイスとの相性も抜群です。また、リモートストレージ、書き込みの増幅(ライト・アンプリフィケーション)を抑えるキー・バリューセパレーションなど、いくつかの新しいアーキテクチャへの道も開けています。オープンソースのRocksDBコミュニティは、インストレージ(ストレージ内)コンピューティングやストレージクラスメモリ(SCM)などの新しいストレージ技術を探求し続けているため、このアーキテクチャの将来保証にも期待できます。
ChakrDB自体も将来に備えており、現在は各仮想ノード(vNode)が抽象的なKVレイヤーの下でRocksDBを基盤のストレージエンジンとして使用していますが、将来的に必要に応じて他のストレージエンジンにプラグインするという選択肢もあります。
クラウドまたはリモートストレージ
今日のクラウドネイティブアプリケーションの多くが、コールドデータをS3やクラウド内(Elastic Block Store(EBC)、Azure Managed Diskなど)にデータを保存するようなユースケースを提供しています。インストレージ(ストレージ内)コンピューティングデバイスがより普及するに従って、研究者たちはコンパクション(圧縮)のようなバックグラウンドタスクをどのようにリモートデバイスにオフロードするかということを探し求めています。このようなユースケース全般に対応するためには、DBがリモートストレージをサポートすることが重要です。
RocksDB環境とNutanixのブロックストアレイヤーを組み合わせることで、ChakrDBはあらゆるタイプのクラウドやリモートストレージ上で動作するようになります。私たちは現在まで、物理ディスク上、Nutanix仮想ディスク上、そしてAzure Kubernetes Service(AKS)とAzureストレージを用いたAzureにおいて、ChakrDBを動かすことができています。
アーキテクチャ
ChakrDBの各インスタンスには、いくつかの内部モジュールがあります。
APIインターフェース
現在、APIインターフェースレイヤーでは、Key-Valueデータに基づくAPIを公開しています。将来の開発で、より機能豊富なAPIを公開する予定です。ChakrDBはRocksDBのAPIを軽量な分散レイヤーで使用しているため、RocksDBを使用しているアプリケーションは簡単に代わりにChakrDBを利用できるからです。
スキーママネージャ
スキーママネージャは、ChakrDBクラスタ内の仮想ノード(vNode)をまたがってのスキーマ操作のワークフローをオーケストレートします。
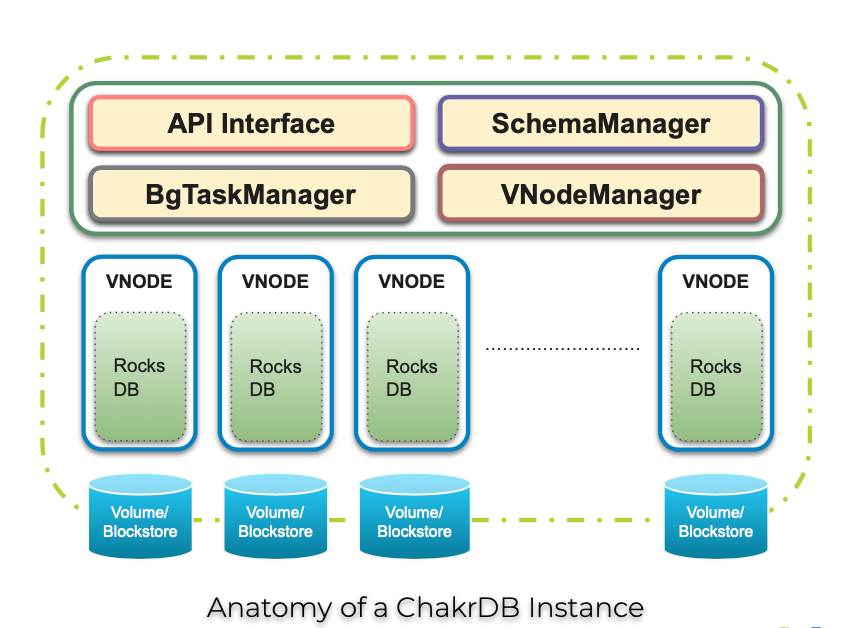
BgTaskManager
このモジュールは、各仮想ノード(vNode)のコンパクション、フラッシュ、テーブル作成、ガベージコレクション(GC)などのバックグラウンドタスクを監視することによって、仮想ノード(vNode)のパフォーマンスを追跡します。必要な統計情報を収集し、分析し、必要に応じて是正措置(フラッシュ、コンパクションなどの起動)を行います。
VNodeManager
VNodeManagerは、仮想ノード(vNode)の起動や停止など、すべての仮想ノード(vNode)ライフサイクル・オペレーションを調整する一方で、仮想ノード(vNode)へのすべてのI/Oも管理します。このモジュールは、クライアントからの I/O を複数の 仮想ノード(vNode)に分散し、仮想ノード(vNode) の応答を収集し、クライアントに送り返します。また、vNodeManagerは、仮想ノード(vNode) 間のリソース共有に関連する判断も行います。
ChakrDBクラスタ
ChakrDBクラスタでは、ChakrDBクラスタをどこへ配置展開できるのかを見ていきましょう。ChakrDBはコンテナ化されているので、どのK8s環境でもポッドで動作させることができます。Nutanixの分散ストレージや、任意のクラウドストレージプロバイダー(AWS、Azureなど)上でK8sプラットフォームをホストすることができます。
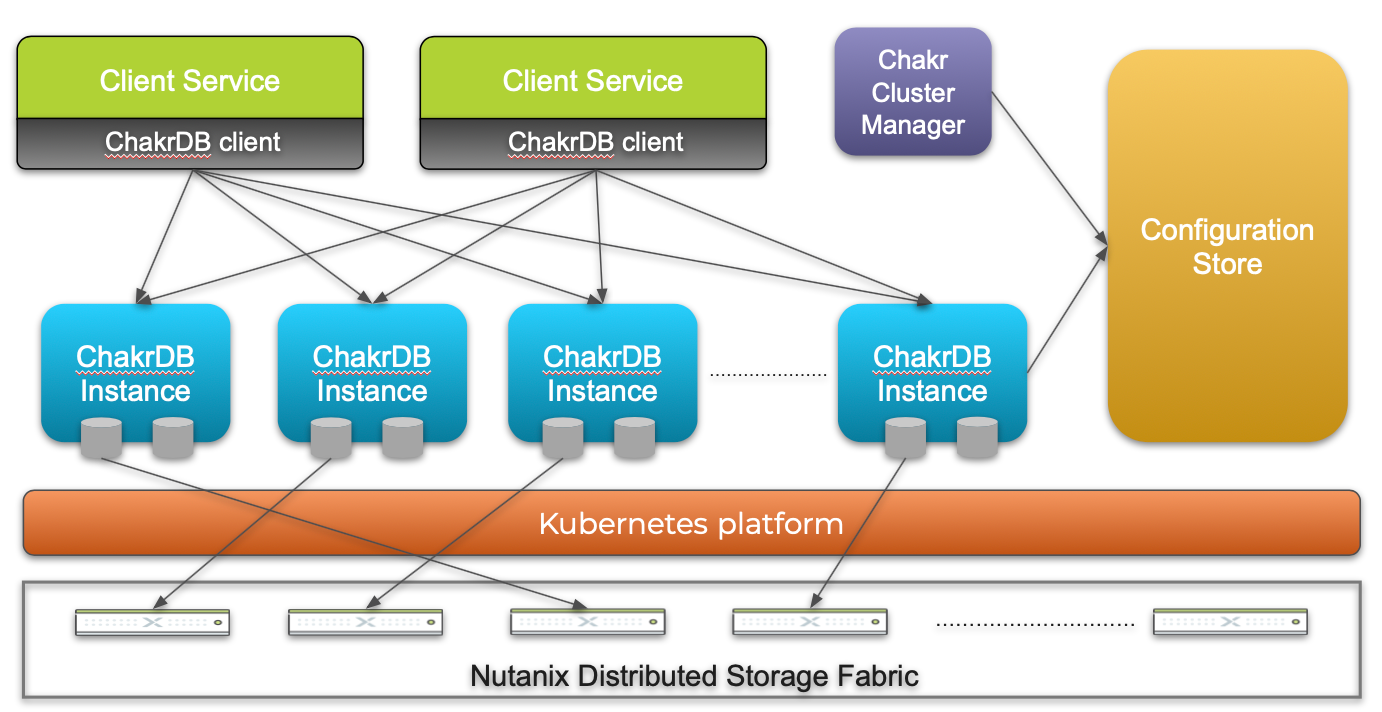
ChakrDBクラスタには、4つの主要なコンポーネントがあります。
ChakrDBインスタンス
データパス全体を管理するコア部分であるChakrDBインスタンスは、仮想ノード(vNode)とそのストレージをホストします。ストレージはNutanix、AWS-EBS、またはAzureから選択できます。
Chakr クラスタマネージャー
Chakr クラスタマネージャーは、ChakrDBクラスタのすべてのコントロールプレーントラフィックを処理します。このモジュールは、クラスタを開始するChakrDBインスタンスの数、ChakrDBインスタンスでホストされる仮想ノード(vNode)の数、シャードと仮想ノード(vNode)をどのようにマッピングするか、スケールアウト時にインスタンス間で仮想ノード(vNode)をどのように移動させるかなど、クラスタの大半の判断を実施します。いったんChakr クラスタマネージャーがこの構成を確立すると、構成ストアに保存されます。私たちは現在、あらゆるクラウドK8sプラットフォーム上でこれら全てのコントロールプレーンワークフローを自動化するK8sオペレータを開発中です。
コンフィグレーションストア
コンフィグレーションストアは、シャードマッピング、インスタンス情報、データベーススキーマを含むすべてのChakrDB設定の詳細を保存します。現在、このモジュールはZookeeperに格納されており、すべてのChakrDBインスタンスと仮想ノード(vNode)の状態設定の中心的参照元となります。
クライアントライブラリ
クライアントサービスは、ChakrDBクライアントライブラリを使用してChakrDBインスタンスと通信することができます。このクライアントライブラリは、コンフィグレーションストアからシャードマッピングを取得し、その情報を使って適切なChakrDBインスタンスに直接リクエストを送り、余分なホップを回避します。そして、クライアントのリクエストを複数のChakrDBインスタンスへ分散し、そこからレスポンスを収集し、クライアントへ送信します。
アーキテクチャのハイライト
ChakrDBは内部でも外部でもそれぞれにリニアにスケールすることができます。ChakrDBインスタンス内の仮想ノード(vNode)をスケールさせることができますし、ChakrDBインスタンスはクラスタを拡張するためにChakrDBインスタンス自体をリニアにスケールさせることができます。これらのワークフローはすべてバックグラウンドでシームレスに実行され、ユーザーのI/Oを妨げることがないように設計されています。
強力な一貫性とレジリエンスは、どんなストレージソフトウェアにとっても重要な要件です。あらゆるクラウドK8sプラットフォーム(Amazon Elastic Kubernetes Service(EKS)、Google Kubernetes Engine(GKE)、Azure Kubernetes Service(AKS)など)は、高可用性を備えたコンピュートとメモリを提供できますし、一方であらゆる高可用性クラウドストレージ(EBS、Azure managed disks、S3など)であれば一貫性と高可用性を備えたストレージを提供することができます。基盤であるクラウドプラットフォームは、すでにコンピュート、メモリ、ストレージの高可用性を提供しているため、ChakrDBに追加のレプリケーションを組み込む必要がなく、非常に軽量なDB分散レイヤーを実現しています。
また、ホストの障害によりうまく対応するため、K8sでは同じホストに2つのChakrDBインスタンスを配置できないように、アンチ・アフィニティ(反親和性)ルールを追加しています。
ChakrDBはパフォーマンスと拡張性に向けた設計になっています。仮想ノード(vNode)ベースのシャーディング設計により、RocksDBがWrite-Ahead Log(WAL)のボトルネックにならないようにし、複数のRocksDBインスタンスにI/Oを分散することで並列性が実現され、書き込みスループットを大幅に向上させています。また、RocksDBインスタンス間でストレージ仮想ディスクを並列に使用することで、読み取りスループットも同様に向上し、ChakrDBは分散ストレージファブリックの潜在能力を完全に活用することができます。
ChakrDBのパフォーマンスを向上させるために、組み込みモードとリモートモードのいずれかを選択することができます。組み込みモードでは、Nutanix Objects(Amazon S3やAzure Blob Storageに似たブロブストレージサービス)のようなクライアントサービスのプロセス空間にChakrDBインスタンスをライブラリとして埋め込むことができます。この機能により、サービスは、組み込まれたインスタンスとローカルで通信しながら、他のChakrDBインスタンスとリモートで通信させることができます。埋め込みモードの環境では、リモートプロシージャコール(RPC)のオーバーヘッドを削減することで、メタデータの低遅延を実現することができます。
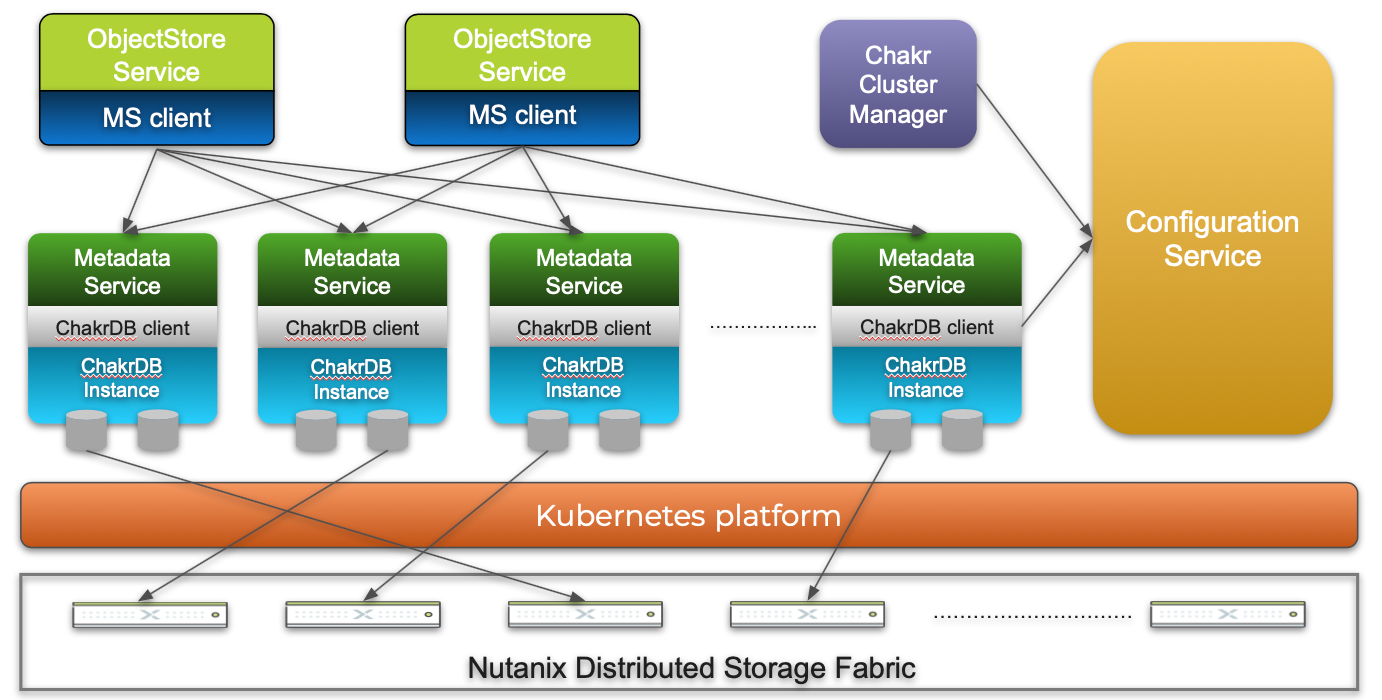
組み込みモードは、ステートフルなサービスに対して非常に効果的です。メタデータサービス (Objectsのメタデータを管理するステートフルサービス)のシャードマッピングがChakrDBのシャードマッピングと重なるように、ChakrDBをObjectsと統合しました。そのため、組み込みモードでは、メタデータサービスインスタンスのシャーディングロジックに基づくリクエストは、常にローカルの組み込みChakrDBインスタンスによって処理されます。この密接な統合と、ローカルのChakrDBインスタンスがObjects内のメタデータサービスシャードの全データを提供することが保証されているため、メタデータサービスはキャッシュ層を維持しながら、読み取り後の一貫性を実現し、スループットとレイテンシーを大幅に改善することが可能です。
スケーラビリティ
Nutanix Objectsの一部として配置されたChakrDBを、社内のクラスタで本稼働テストを実施しました。ここでは、環境を非常に大規模にした際に得られた結果をご紹介します。
注:実際の本運用環境クラスタでは、この規模に到達するまでにより長い時間がかかると思います。
- QAチームが導入した最大規模のクラスタでは、ChakrDBインスタンスが約1,024台、各ChakrDBインスタンスに仮想ノード(vNode)が4台、合計約4,000台の仮想ノード(vNode)が展開されました。
- 社内クラスタの一つでは、128ノードのChakrDBクラスタに約25TBのデータを約75バイトのキーでプッシュしました。これは、ChakrDBインスタンスあたり約200GB、600MBのキー、仮想ノード(vNode)あたり約50GB、150MBのキーに相当します。
- 一つのChakrDBインスタンスに11GBのメモリを割り当てると、約8バイトのキー、約1.6TBのデータを処理することができました。このインスタンスには8つの仮想ノード(vNode)が含まれ、各仮想ノード(vNode)は1バイトのキーで約230GBのデータを保持しました。この結果は、ChakrDBのリソース効率の高さを示しています。
- これらのChakrDBクラスタのほとんどは、4ノードのNutanixクラスタ上に展開しました。これは、ChakrDBが分散ストレージファブリックの潜在能力を十分に活用できることを示しています。
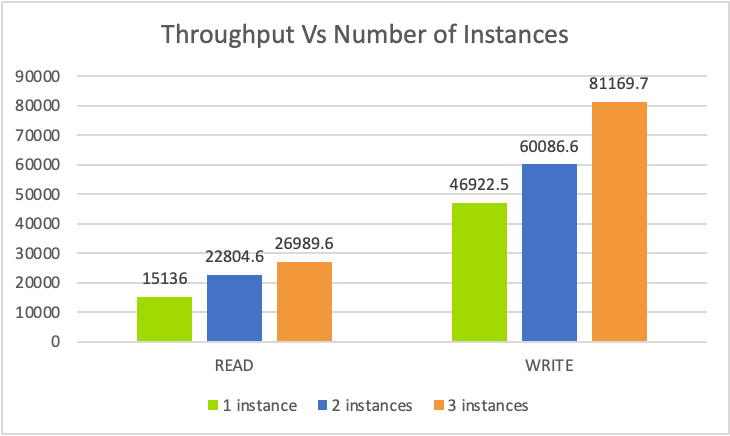
上記のグラフは、ChakrDBインスタンスをリニアに拡張した場合のスループットを示しています。この数値にはまだ改善の余地があり、次回のChakrDBブログでは、読み込み、書き込み、スキャン操作についてのより詳細な結果を公開する予定です。Percona Liveで行った最近の講演では、ChakrDBのアーキテクチャと、最近のRocksDBの強化点について詳しく説明しています。
おわりに
ChakrDBは、クラウドで生まれた、クラウドのためのKVSになりつつあります。現在、複数のお客様が、ストレージ、コンピュート、メモリをインフラHAだけに依存する、ChakrDBをObjects環境の一部として稼働させることで、優れた結果を出しています。
RocksDBレイヤーのバグは、非常に小さいものであっても、ストレージに影響を及ぼす可能性があります。このようなバグからデータを守るために、非同期バックアップ技術や様々なステージでのチェックサム計算を追加することを検討しています。RocksDBの最新バージョンでは、ソフトウェアの競合が永続化することを事前にくいとめるための改善されたチェックサム技術が搭載されています。
前の節で説明したように、我々はメモリ使用量に対するデータ、CPU使用量に対するスループットで優れた比率を達成しました。
インスタンス内では複数のvNodeを用いることで、そしてインスタンスレベルでは複数のインスタンスを追加することで、リニアな拡張性を実現しました。ですが、我々にはクライアントライブラリと VNodeマネージャ レイヤーにおけるリニアな拡張性の内の最適化とオーバーヘッド削減を実現するために、まだやるべきことがあります。
これまで、K8sベースのNutanixマイクロサービスプラットフォーム(MSP)上の大規模クラスタで、環境の拡張性が失われたり、大きなボトルネックに遭遇したことはありません。つまり、1つのクラスタで数百テラバイトのキーバリューデータを保存できるのです。一般的にはクラスタのサイズはノードのストレージキャパシティ、または分散されていないクライアントによる制約を受けることになります。分散型や組み込み型のクライアントであれば、非常に膨大なスループットやストレージだけでなく非常に多くのノード数を拡張できます。
私たちがRocksDBの読み込み、書き込み、および圧縮操作にまたがってChakrDBのスレッドモデルを徹底的にチューニングした結果、パフォーマンスが向上しました。今後のブログで、RocksDBとChakrDBのパフォーマンスの取り組みについて詳しく分析する予定です。
Nutanix Objects製品(ChakrDB搭載)は、その高いパフォーマンスとスケーラビリティが有名です。バックアップやセカンダリーストレージのワークロードに加えて、ビッグデータ分析のような大規模S3ワークロード、機械学習(ML)、人工知能(AI)など、様々な高性能のワークロードへの対応が検討中です。
ChakrDBは、ハイブリッドマルチクラウド環境をサポートするための以下の機能を備えたKVSへと進化しています:
- クラウドネイティブ: K8sプラットフォームをベースとするあらゆるクラウド上で動作可能。
- あらゆるクラウドストレージ : K8sプラットフォーム上のコンテナに接続可能な任意のクラウドやリモートストレージにデータを書き込める。
- クラウド型の簡単なワークフロー:K8sとソフトウェア定義のストレージを活用した展開、スケールアップ、スケールアウトのワークフロー。
- 強固な一貫性、HA、リジリエンス : ChakrDBはクラウドインフラの機能を利用し、レプリケーションや分散コンセンサスプロトコルを追加するような複雑さを回避。
- 性能のスケールアウトと低レイテンシー : RocksDBの基盤に軽量な分散レイヤーを組み合わせることで、クラウドスケールのアプリケーションに対して非常に高性能さと低レイテンシーを実現。
Nutanixは、現在進行中の複数のプロジェクトや製品でChakrDBをプロトタイプで利用し、すぐれた初期成果を上げています。
- 長期バックアップソフトのキャッシングやステージングレイヤーとして
- AOSに実装されているCassandraのリプレースとして
- Postgresの分散ストレージエンジンとして
ChakrDBはプレーンなKVSとしてスタートしましたが、現在では以下のような先進的な機能の要望が増えています。
- セカンダリのインデックス
- 仮想ノード(vNode)の拡張、インスタンス間での仮想ノード(vNode)の移動が自由かつ容易にすること
- 仮想ノード(vNode)をまたがる分散トランザクション
これらの機能やその他お機能についての実装は続きます、今後もブログで進捗をご紹介していく予定です。また、ChakrDBをオープンソース化し、これまでお世話になったRocksDBコミュニティとメリットを共有できるようにする予定です。
謝辞
この取り組みは、ChakrDBチーム全体によって支えられています。- Parmpreet Singh, Rituparna Saikia, Ronak Sisodia, Sweksha Sinha, Jaideep Singh, Yasaswi Kishore.
このプロジェクトの設計とデザインにおいて、継続的に指導してくれたKaran Guptaに大きな感謝を捧げます。また、コンテンツの詳細確認とフィードバックをくれたDheer MogheとKate Guillemetteにも感謝致します。