


本記事は2021年11月24日にGary Little氏が投稿した記事の翻訳版です。
原文はこちら。
皆さん、ようやくここまで来ました。

全面公開です。私は2013年からNutanixのパフォーマンスエンジニアリンググループで働いています。私の意見は偏っているかも知れませんが、それによってNutanixのストレージの性能についてはそれなりの経験と実績を持っています。すでにNutanix上でデータベースワークロードを稼働させている多くのお客様がおられます。しかし、これらのハイパフォーマンスなデータベースを依然として従来型のストレージ上で稼働させるとどうなるでしょうか?
2017年の.Nextでプレゼンテーションを行った際の資料を掘り出してきて、それに最近のプラットフォーム(AOS 6.0とNVME+SSDのプラットフォーム)のパフォーマンスを追加しました。このランダムReadのマイクロベンチマークのパフォーマンスは2倍以上にもなっています。HCIシステムを数年前にご覧になって、その際に必要なパフォーマンスが出ないと結論づけた方 ― もしかすると、今日出荷されているハードウェアとソフトウェアのシステムでは皆様の要件を達成できるかも知れません。
更に詳細は下に。
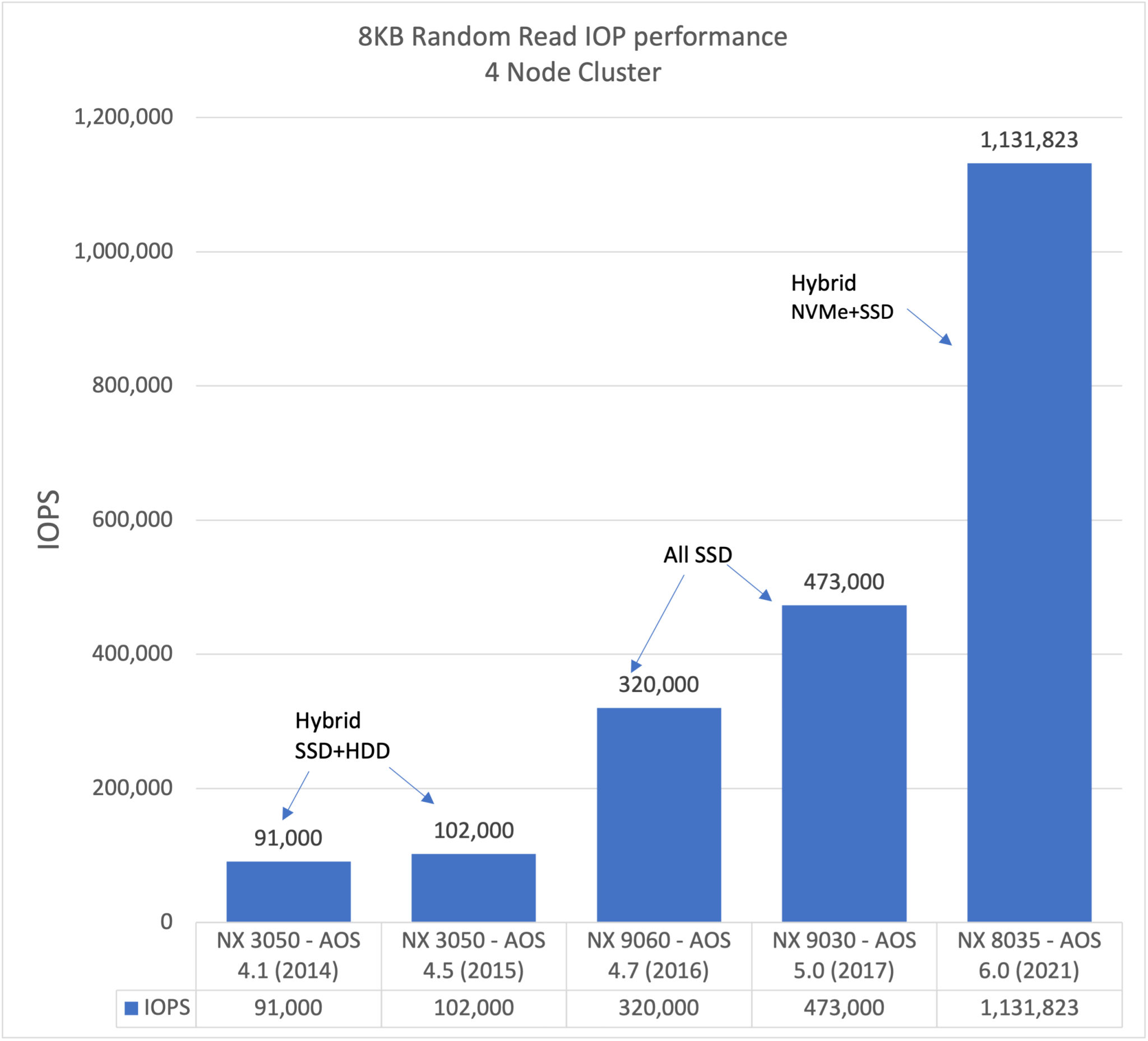
私のラボの中にあるまだ出荷されていないビルド(※訳注:本日時点で6.1としてすでに出荷開始されています)のAOSが動作しているもう一つのクラスタを見てみましょう。このクラスタも2枚のoptaneドライブとRDMAに対応したNICを搭載しています。この4ノードのシステムでのマイクロベンチマークの結果は?
| ワークロード | 結果 | ノート |
| 8KB ランダムRead IOPS | 1,160,551 IOPS | 部分的にキャッシュされている |
| 8KB ランダム Write IOPS | 618,775 IOPS | RF2でフラッシュメディアに完全にレプリケーションされている |
| 1MB シーケンシャル Write スループット | 10.64 GByte/s | ネットワークスピードの上限に到達、RF2でフラッシュメディアに完全にレプリケーションされている |
| 1MB シーケンシャル Read スループット | 26.35 GByte/s | ホストあたり 6.5 Gbyte/s です、データローカリティのおかげです! |
| 8KB Write 単独 IO レイテンシ | 0.2 ミリ秒 | 200 マイクロ秒 – RF2でフラッシュメディアに完全にレプリケーションされている |
| 8KB Read 単独 IO レイテンシ | 0.16 ミリ秒 | 160 マイクロ秒 – 永続メディアから (キャッシュからではない) |
マイクロベンチマークのヒーローナンバー
印象的なのは とてつもないIOPSとスループットの数字だけではなく、単独のIOの微細なレイテンシ(応答時間)です。特にWriteのレイテンシは200マイクロ秒でクラスタ内の2つの異なるノード上の2枚のフラッシュに書き込んだときの数字です。Readの160マイクロ秒のレイテンシはCVMのキャッシュからではなく、Optaneドライブの永続ストレージからのものです。
データベースベンチマーク
上記のIOの数値は我々のX-Rayツールから展開されたfioによって取得されたものです。しかし、我々はマイクロベンチマークの数字は単なる理想的な状況下において単独のIOサイズ、パターンで計測した「ヒーロー」ナンバーであるということを知っています。
お客様は普通はデータベースから見たIOパフォーマンスに最も注意をはらいます。データベースワークロードは一般にはIOサイズ、IOデプス(多重度)、Read、Writeがミックスされたもので、マイクロベンチマーク検証よりも大きなワーキングセットのサイズです。これがあらゆるストレージベンダーのIOベンチマークの真実です。
それでは特徴の異なる2つのデータベースのベンチマークの結果を見てみましょう。
- 単独ノード上でHammerDBのTPC-Cライクなワークロードを動作させている単独のMicrosoft SQL Server
- 4ノードのNutanixクラスタ全体でSLOBを稼働させている一連のOracleデータベース
| ワークロード | 結果 | ノート |
| 単独のMicrosoft SQL Server, 単独ノード, HammerDB TPC-Cライクなワークロード | ~100,000 IOPS 、1ミリ秒未満の応答時間 | SQL Server VM上の16vCPUが制限になっている |
| 4ノード全体でSLOBを稼働させている8台のOracleデータベース | ノードあたり ~125,000 IOPS 、1ミリ秒未満の応答時間 | 4ノードクラスタ上で500,000 IOPS |
データベースのクエリエンジンが生成する (SQL Server, Oracle)
これをどうやって達成してきたのか(多くのパフォーマンスの改善の積み重ね)とデータベースでの結果の詳細見ていきましょう。
パート1 : 選択的最適化
ステップ1. 大きなワーキングセットサイズむけのパフォーマンスの改善
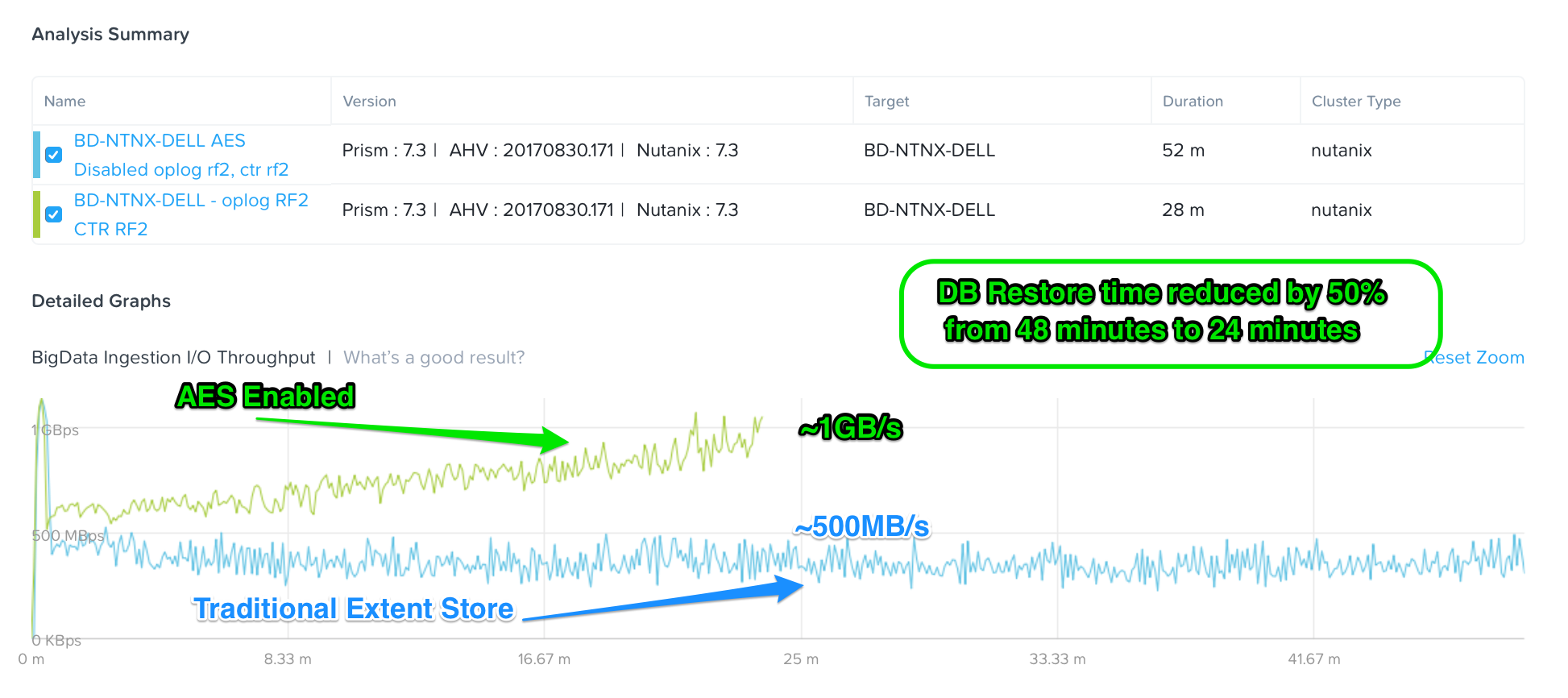
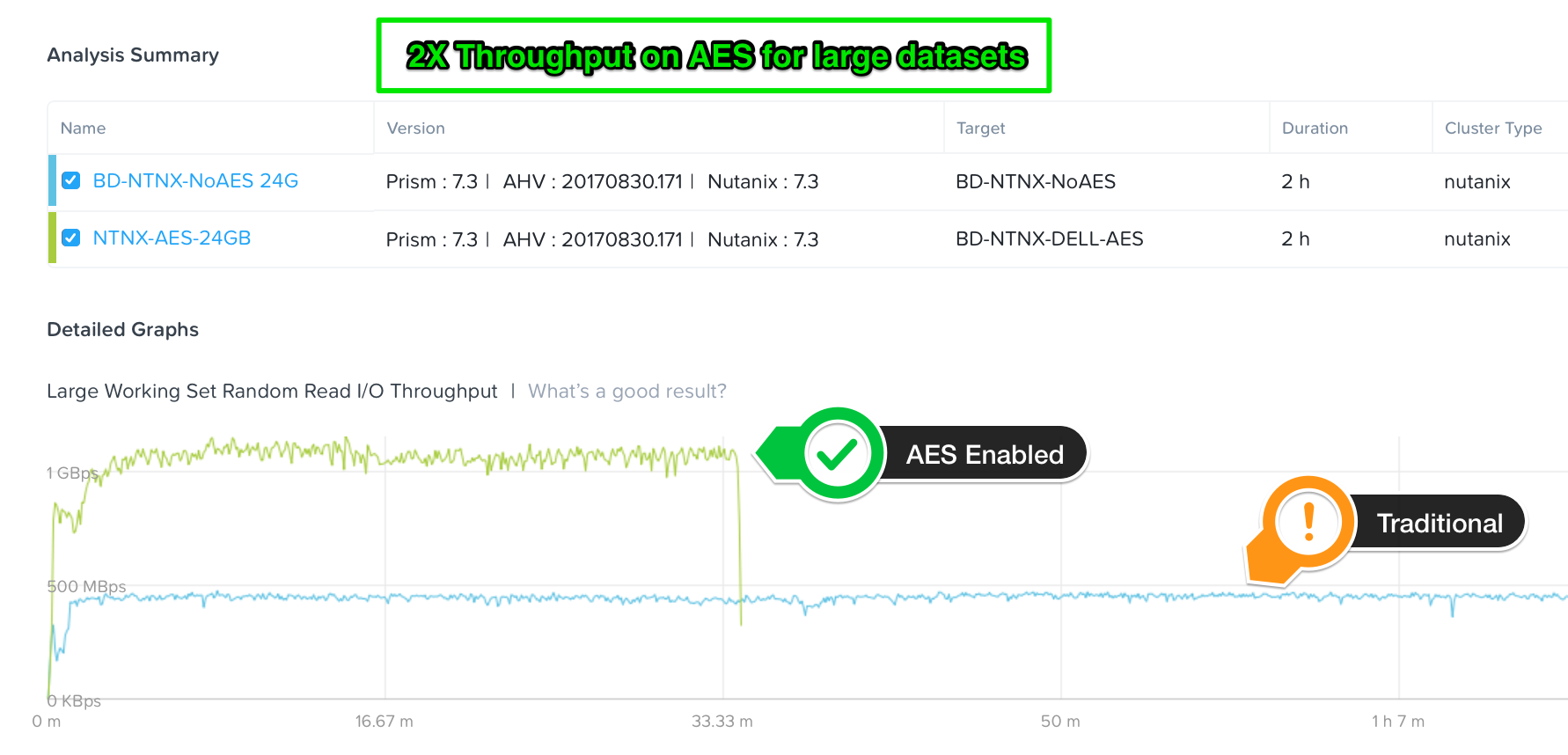
我々はRocksDBをベースとしたメタデータの保管によって、メタデータについてのアクティビティの大部分をCassandraレイヤーから移動させることからはじめました。これによって、本番環境のデータベースでよく見られるような大規模なワーキングセットサイズを利用する場合にメタデータを参照する回数は劇的に削減されます。このひとつの変更だけで、データベースを中心とした2つのユースケースの性能は2倍にもなりました。
- 大規模なワーキングセットでのランダムRead
- スループットの高いデータベースの負荷とバックアップからのリストア
こちらは開発を行っている際に実験を行ったときの生データです。我々はこの機能を自律エクステントストア(Autonomous Extent Store - AES)と呼んでいます。
ステップ2. データベースのログ書き込みの遅延を改善
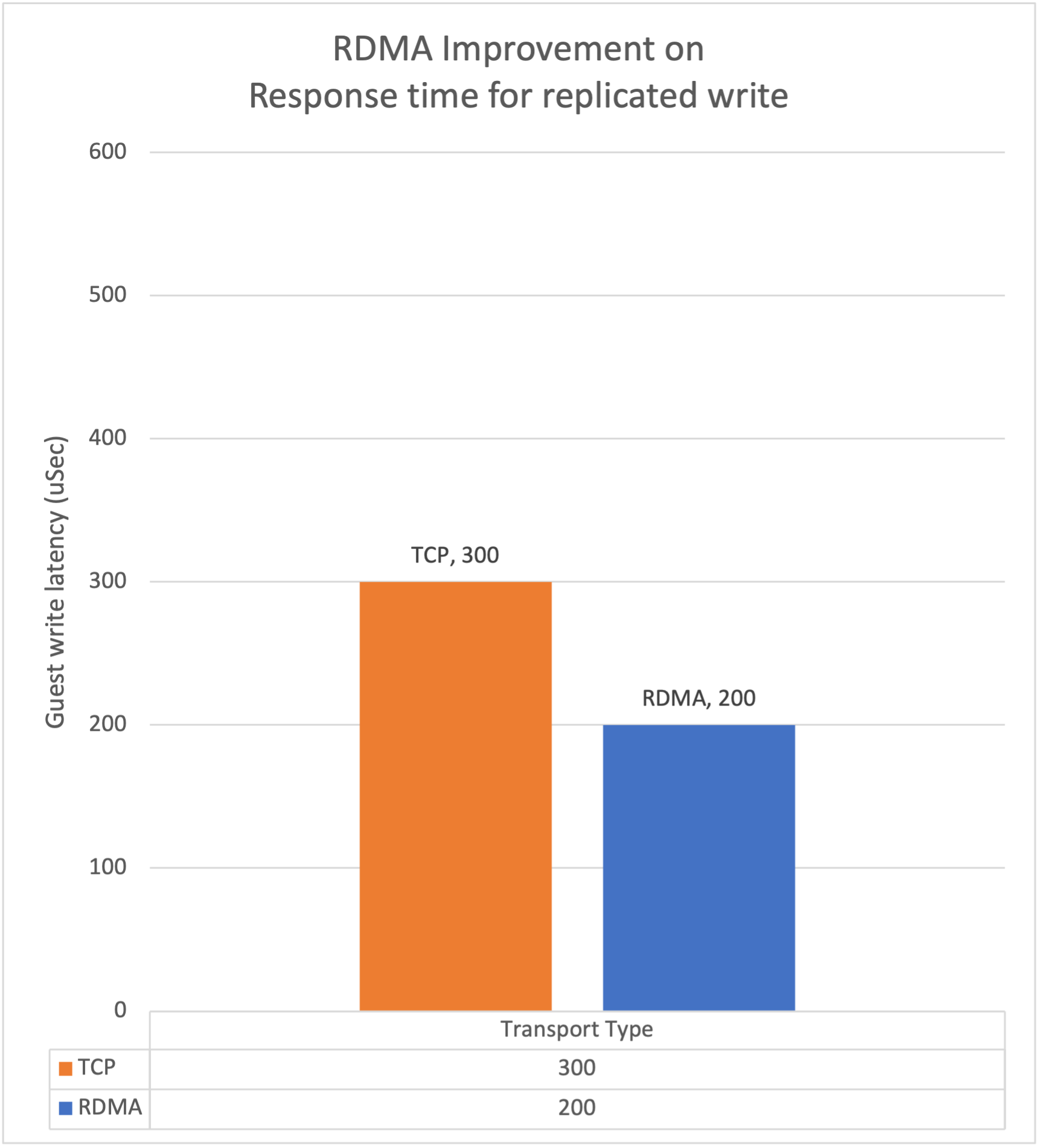
多くのデータベースはトランザクションログのレベルではシングルスレッドで動作しています。シングルスレッドのワークロードで改善を行う方法は、レイテンシを低下させる以外にはありません。Nutanixのようなスケールアウト型のコモディティハードウェア上で動作するソリューションではストレージ装置におけるHAペアのようにNVRAMのポイント間接続を利用することはできません。低遅延のインターコネクトが無いことで、低遅延の書き込みが必要なデータベースをサポートするために必要な機能が制限されていたのです。
我々はストレージコントローラーをパススルーしてNVMEドライブへとアクセスを行うRDMAを実装することでWriteのレイテンシを劇的に低減しました。直近の構成では単独のWriteは2ノードのNANDフラッシュに対しておよそ200マイクロ秒で書き込まれます。我々は低遅延のワークロード向けに必要とされるパフォーマンスを劇的に改善し、インメモリデータベースの認証を得ることができました。
ステップ3. 効率性の改善とCPUのパス長とオーバーヘッドを低減
さて、Nutanix特有のボトルネックの多くを取り除いてきましたが、ここからはOS/カーネル深いレベルの最適化にフォーカスをあてます。
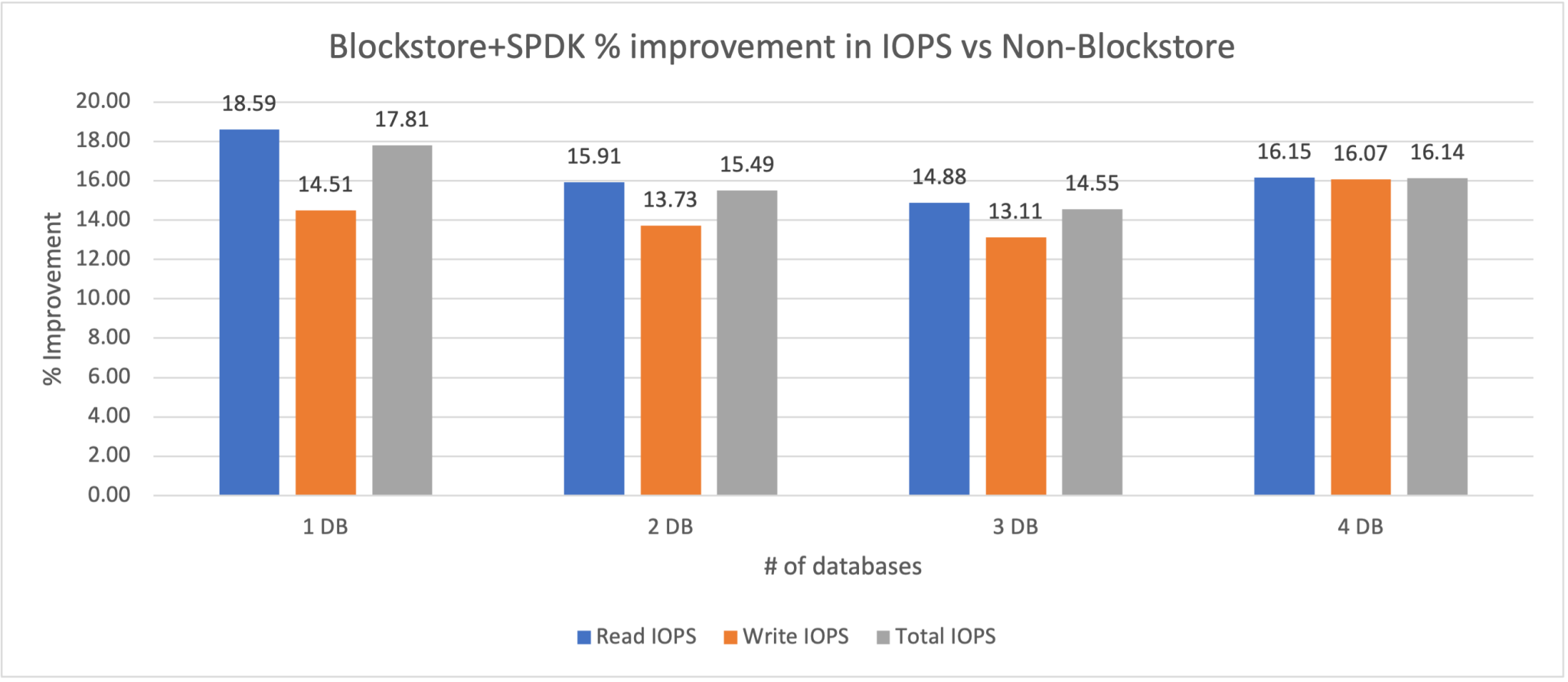
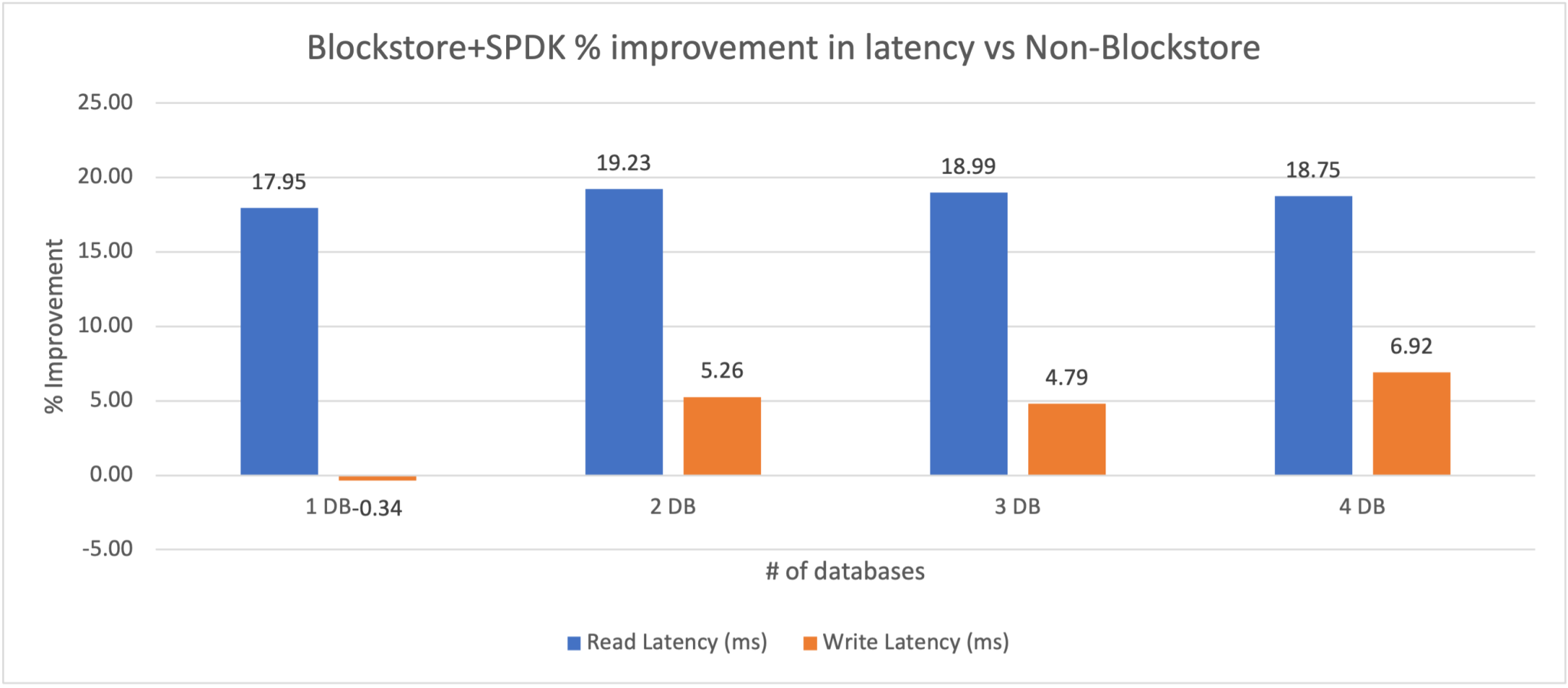
2020年に我々はBlockstoreとSPDKをリリースしました ― これは我々がNVMEデバイスに対して完全にユーザーランドのパスでアクセスでき、システムコールを利用してカーネル入る必要がないということを意味します。これはパフォーマンスの改善を実現するだけではなく ― 効率性を向上させることも実現します。
当時の私のラボでの検証を行った際にはデータベース自身から見て10〜20%の改善が見られています。これらの改善は効率性の改善です ― つまりパフォーマンスを向上させるために起きるトレードオフはありません。唯一あったとすればNutanixの開発チームのコアデータパスチームの努力です!
ステップ4 – リフト & シフトエクスペリエンスの改善
我々のデータベースに関連する最も新しいイノベーションはデータベースワークロードのリフト&シフト時のパフォーマンスの改善です。多くのお客様は何千ものデータベースを抱えておられ、それらは従来型のインフラストラクチャからよりモダンな基盤へと移す必要があります。その先がパブリッククラウドか、Nutanixかは関係ありません。これまでは幾ばくかのリファクタリング、よくあるものとしては仮想ディスクを複数利用した並列性の向上などをおこなわずにパフォーマンスを最大化することは不可能でした。
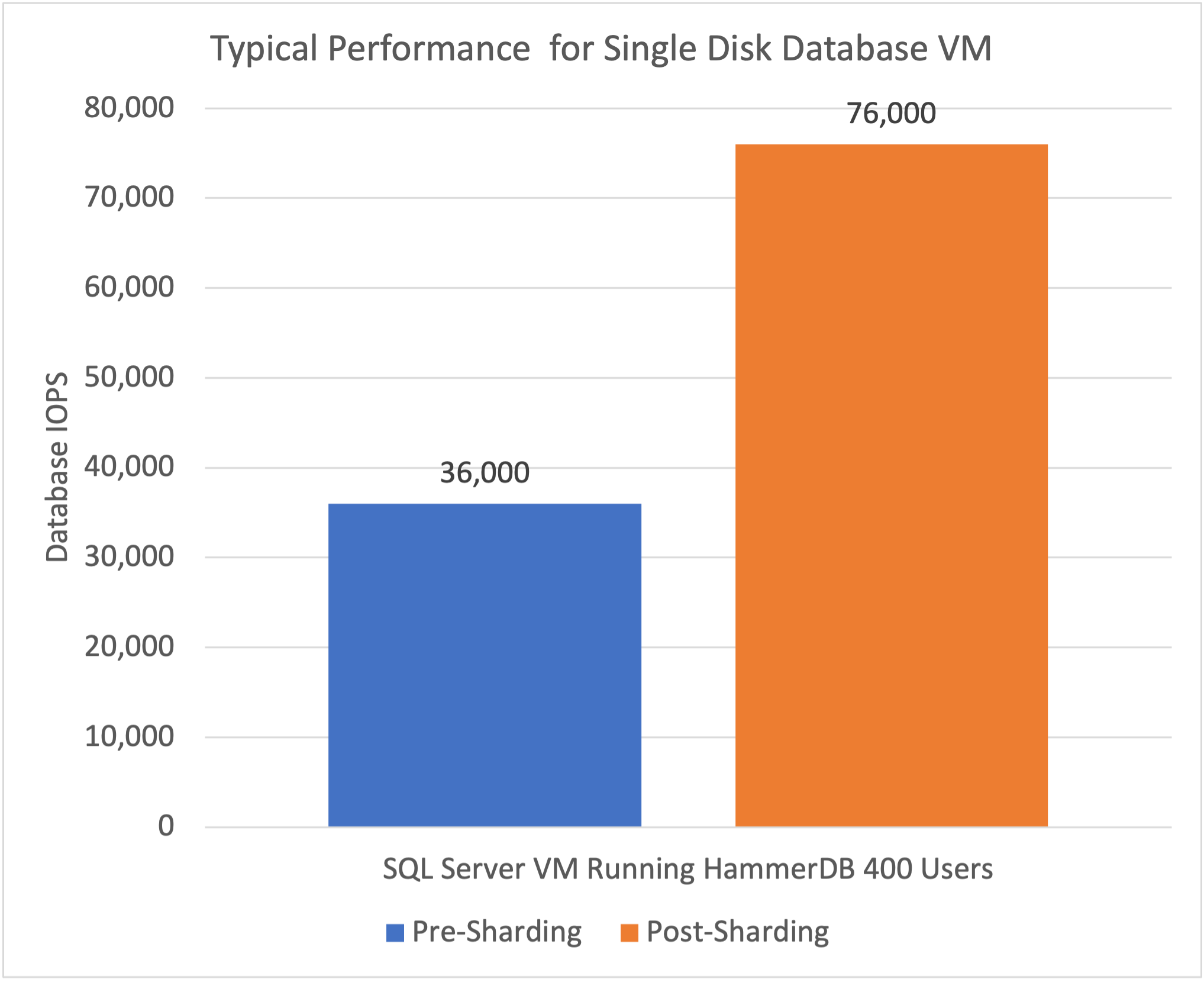
Nutanixのディスクシャーディングでは管理者が一切のリファクタリングを行うことなく、Nutanixストレージの並列性を向上させることができるようになりました。すべての変更はNutanix AOS内部のストレージスタックだけで実現されています。
単独ディスクのデータベースにおける性能を2倍以上に改善し、手動で最適化を行った複数の仮想ディスクを利用するようにしたデータベースと同等の性能をインラインで達成したのです。
パート2 – 結果
これらのパフォーマンスについての最適化を追加して – 殆どのデータベースワークロードがNutanix HCI上で動作するという分岐点に到達したのでしょうか?
Microsoft SQL Server
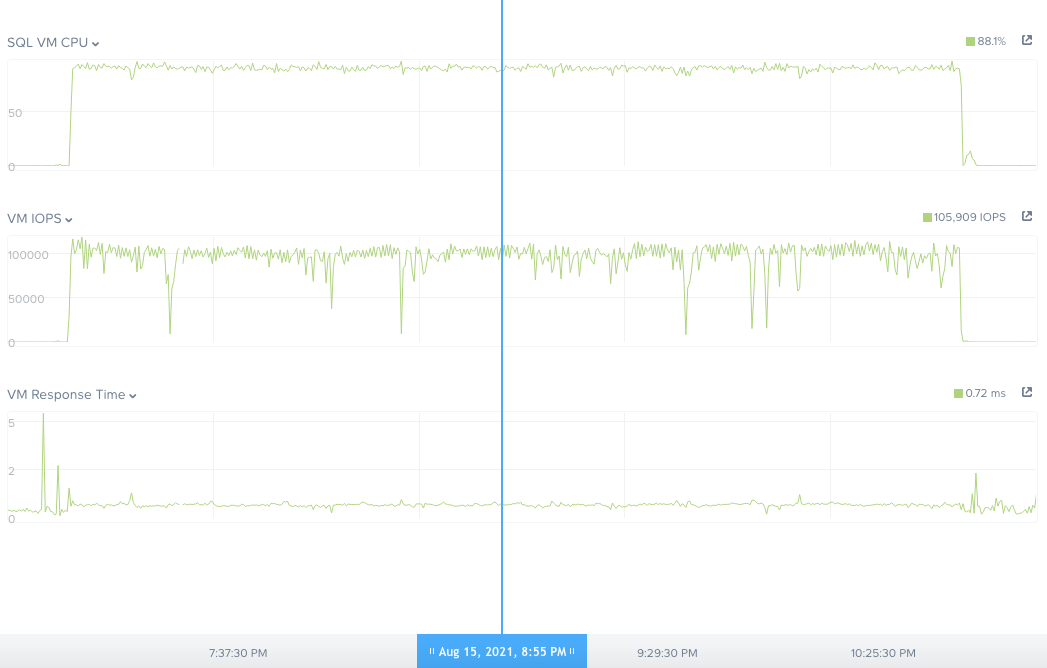
まずはNutanix上で最も広く利用されているデータベース– MS SQL serverでHammerDB(TPC-Cライクなワークロード)を稼働させています。仮想マシンゲストから見て1ミリ秒未満の応答時間で 〜100,000 IOPSが確認できています。ストレージの優れたパフォーマンスによってSQL Server VMの16のコアのすべてが常に忙しくデータベースワークロードをする状態にあります。
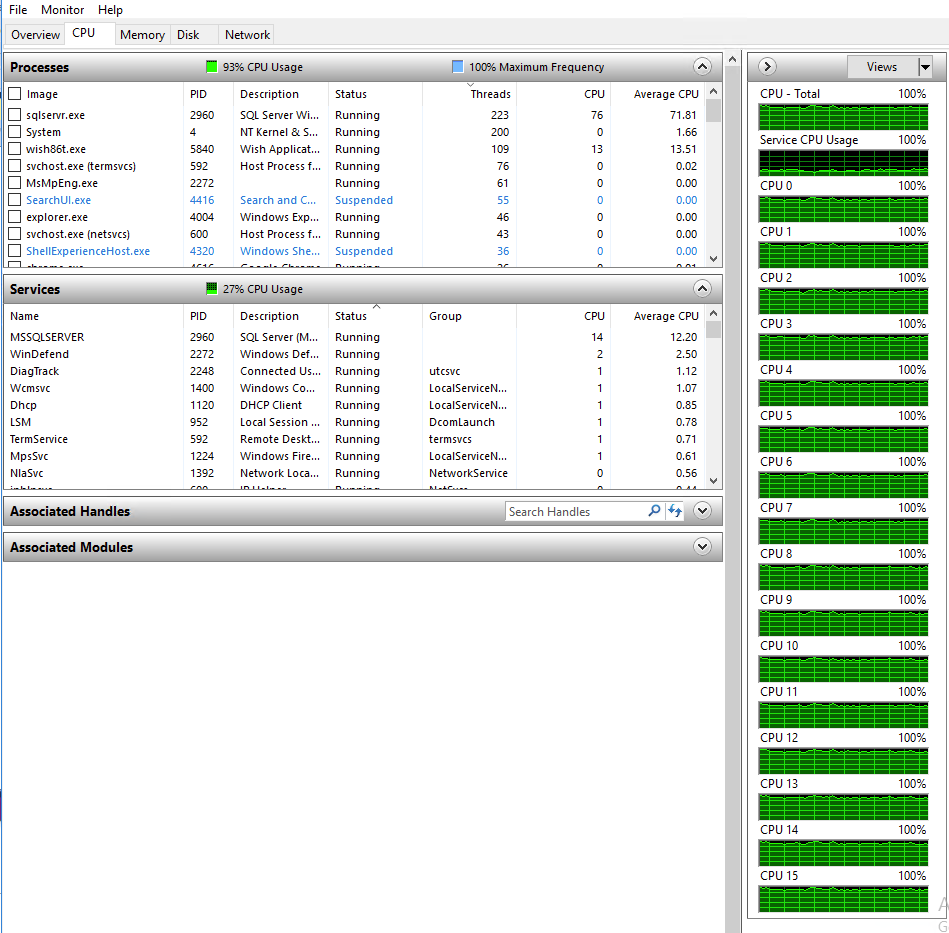
パフォーマンスはベンチマークを流していた数時間一貫したものでした。
PostgreSQL
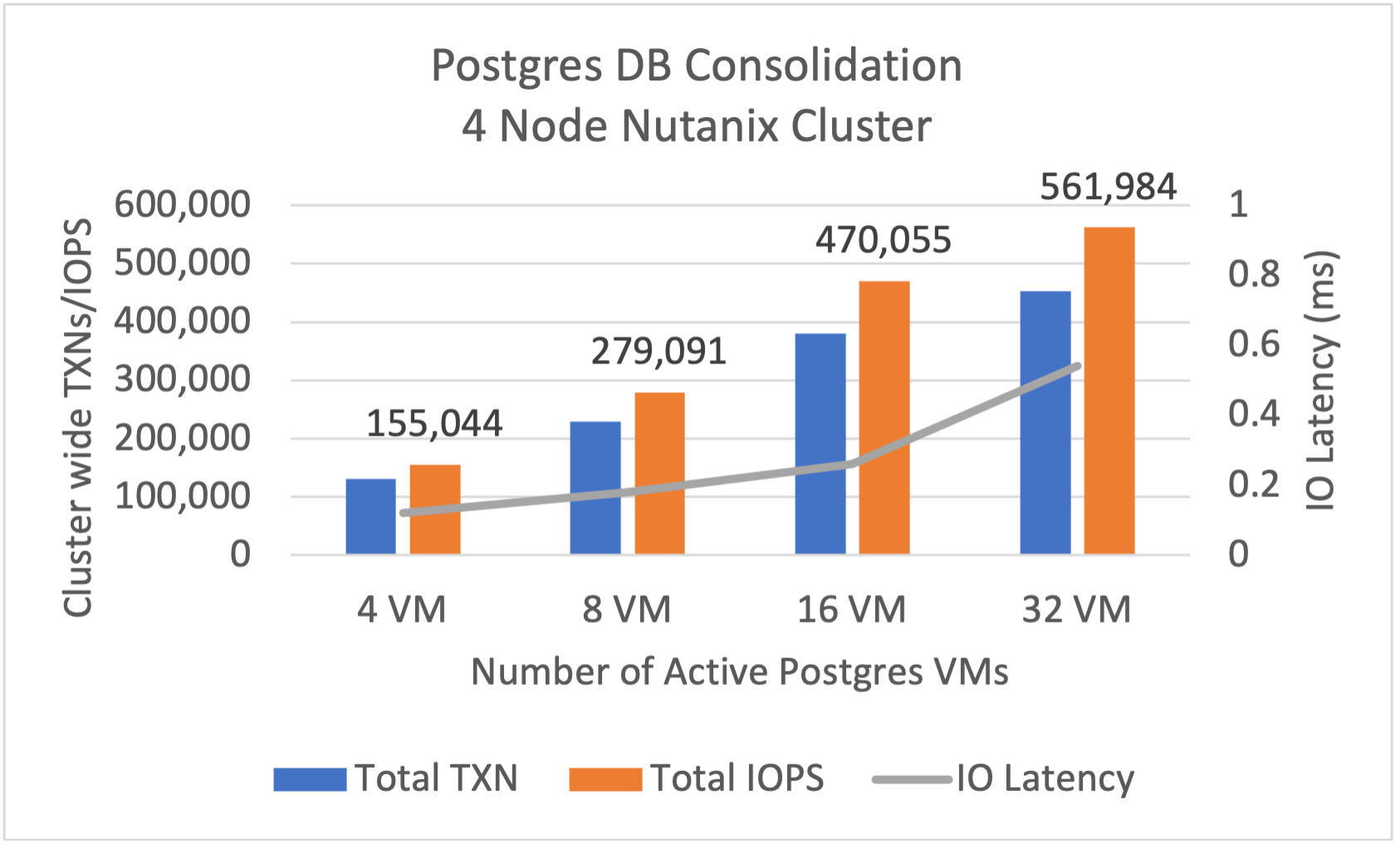
次はPostgres DBを利用して、データベースの統合シナリオを見ていきましょう。4ノードのNutanixクラスタ上でPostgres VMを32まで増やしていきましたが、500,000を超える IOPSを1ミリ秒未満の応答時間で実現しました。
Oracle
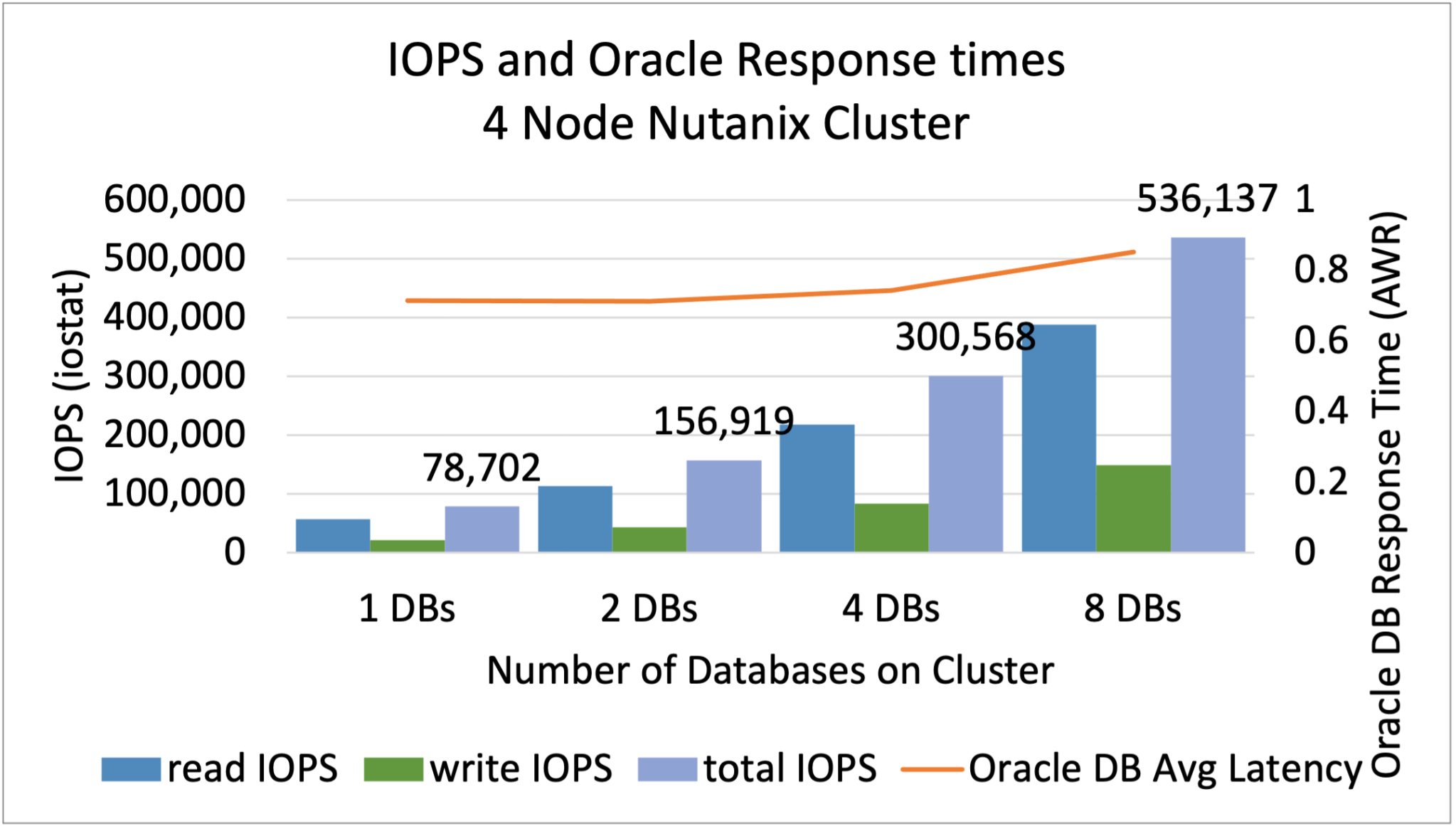
最後に、Oracle DB上でSLOBを稼働させました。Nutanixのストレージは1ミリ秒未満(のレイテンシ)で500,000 IOPSを提供しています。
結論
結論として – 我々は直近の数年で多くのことを実現してきました。2018年頃から我々はコモディティのHCIでデータベースのパフォーマンスを提供するということをミッションにしてきました。まだこの旅は続きますが、2-3年前には不可能だったワークロードを動作させることができるようになっています。