My present client is making me working on a design implying to deploy a XAAS plateform with a lot of security inside (NSX is on the cook list). In our team, i was declared as the nutanix man.
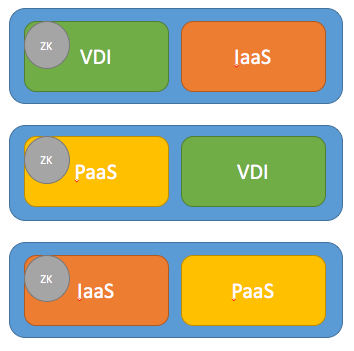
My mission is to determine the best way to isolate storage from diffrent workload :
- we'll have an integration zone, a developpement and a production zone as PAAS.
- Some node will executed heavy VDI (K2 graphic cards will achieve this),
- Then we'll have a IAAS with vcloud SP for the sandbox zone).
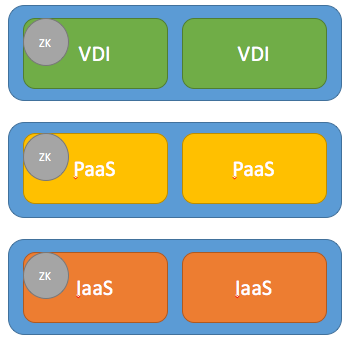
My question is, can I make a 6 node cluster for nutanix / storage point, with 3 volumes pools on all 6 node ?
and more than that what will it implies in terms of storage performance, data protection, data seggregation (security team will challenge me heavily on this part) ?
Last but not least, can I achieve this at the container level ?
best regards,
Thomas CHARLES
Best answer by cbrown
View original