

This post was authored by Jeroen Tielen (Tielen Consultancy) Nutanix Technology Champion
Within Nutanix we have Replication Factor (How many data copies are written in the cluster) and Redundancy Factor (how many nodes/disks can go offline). Both can have a value of 2 and 3. What is what is explained here: Blog Post.
So, when we have a larger cluster, we always recommend using RF3 (Redundancy Factor 3) as the risk is higher that you have multiple nodes/disks go offline at the same time.
During trainings and onsite customer work I often get the question, "what will happen if multiple nodes go offline in Redundancy Factor 2?" In this blog post I will explain different scenarios and their behaviors.
My cluster is 7 nodes and configured with RF2 (Redundancy and Replication) and HA Reservation is enabled.

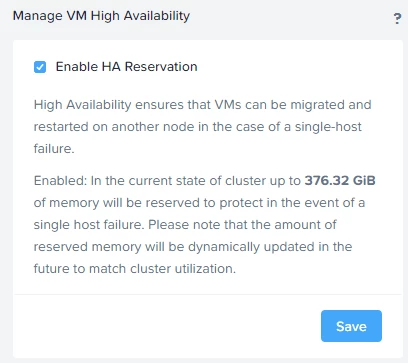
I've got 30 Windows 11 VDI's (Yes, with vTPM ;)) running in the cluster and all load is spread across the nodes. This is the current usage on the cluster:
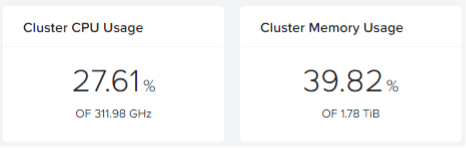
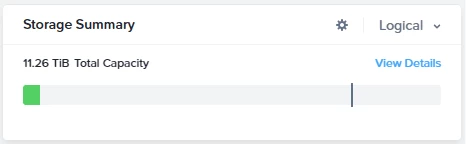
Now 1 node will go offline. Or in my case, I just turn turn it off via IPMI.
HA will kick in and restart the VDI's who were running on the failed node on the remaining nodes (of course if there are enough resources available):

The cluster will also automatically rebuild the storage containers, so Replication Factor 2 is restored over the remaining clusters:
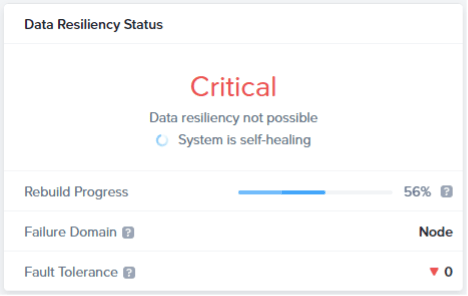
When the rebuild is done, data resiliency is not restored!!! As we have a Redundancy Factor 2 cluster, we can't tolerate an extra node/disk down at the moment.
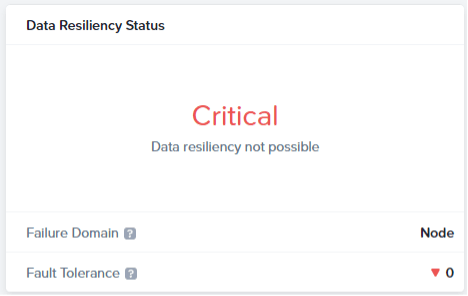
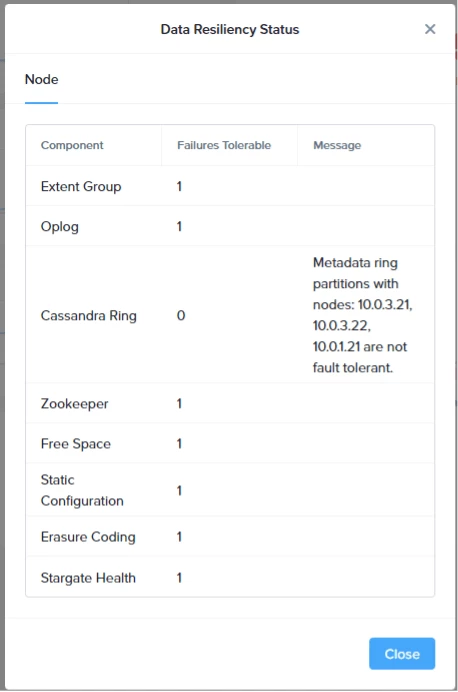
Click on Critical to get a list which component doesn’t support a failure at the moment.
After 30 minutes (CVM not reachable for 30 minutes) the node is being detached from the metadata ring to restore Redundancy Factor 2, and alert A1054 is generated. More info here: Alert A1054

When the node is detached, the cluster has restored Redundancy Factor 2.
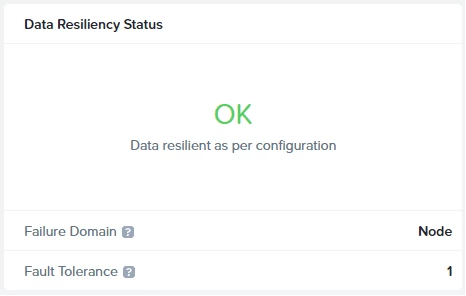
So, we can bring down another node.
- HA failover occurs;
- Replication Factor 2 is rebuild
- After 30 minutes the node is detached from metadata ring
And my cluster is 5 nodes instead of 7. I can continue with this for a while until I have 2 nodes left, just because I can. But for now, I leave it like this. I don’t have a lot of Guest VM's running and available resources are shrinking too as you can see in this screenshot:
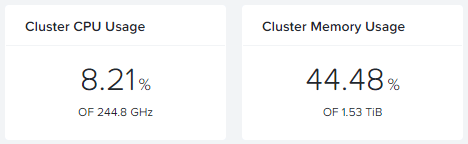
But what would happen if another node went offline, and after Replication Factor 2 is restored (The storage blocks), another node goes offline? So, before the node is removed from the metadata ring.
Long story short, my cluster is dead.
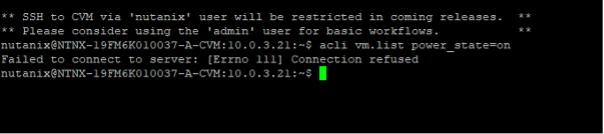
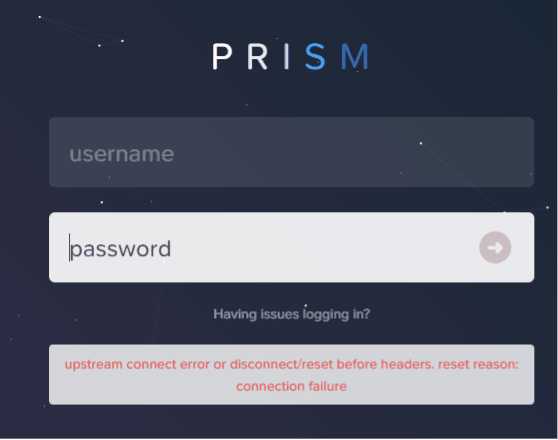
Got my cluster fixed and up and running again. It is now running on 5 nodes and 2 are still offline.

When the nodes are repaired and ready to put back in production just turn them on. When the CVM is running you can add the node back in the metadata ring. In Prism Element navigate to Hardware --> Select Node.
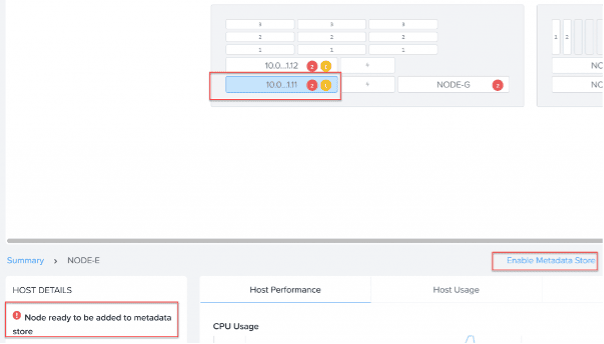
As you can see in the screenshot the node is ready to be added back into the MetaData Store. Click: Enable Metadata Store. The node is now being added back to the cluster.

It is ready to host Guest VM's again.
Note: Keep in mind that this is just informational, when a node/disk is offline take immediate actions to get it back online. Resources are shrinking so probably not all guest vm's can start up again. And for the largers cluster, use RF3.