

I had made a short video on auto scaling Nutanix cluster in AWS using new Nutanix Playbooks. Playbooks offer a visual way to start automating actions in your hybrid cloud. Due to making the video short, I didn't spend a lot of time talking about options that you could set.
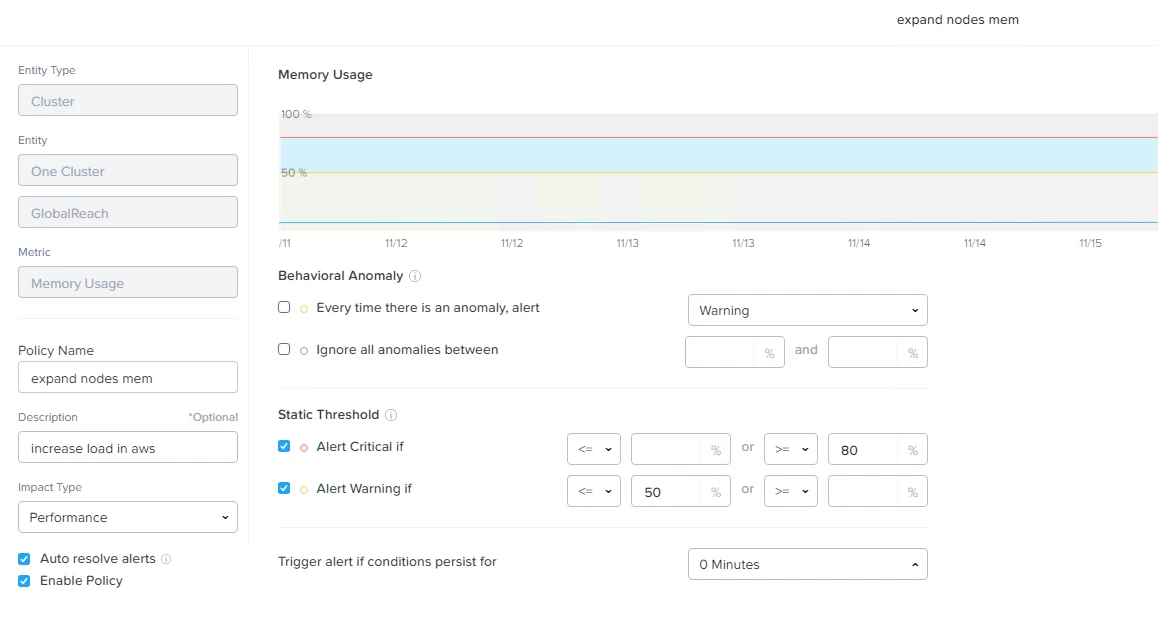
Prism central has a lot of alerts that you can use to trigger the action that you want to take. If you don't see the right “Alert” you can customize one of the existing ones to meet your needs and will be a user defined alert. In my example I was using a critical memory capacity over 80% capacity on adding nodes. If your clusters are typically higher than 10 nodes you might try using a higher percentage based on one node is going to be a lower percentage of memory overall. Likewise you could be more aggressive with picking a lower memory percentage. One thing that you'll want to set as well is the “trigger alert if condition persists for". I didn't have it set so I could easily record the demo but I think it would be quite reasonable to 10 – 15 minute range. This will give you some protection on short lived bursts.
When you go to configure your playbook you can do if else statements triggering on whether the alert was critical or if it was a warning from the custom defined alert.
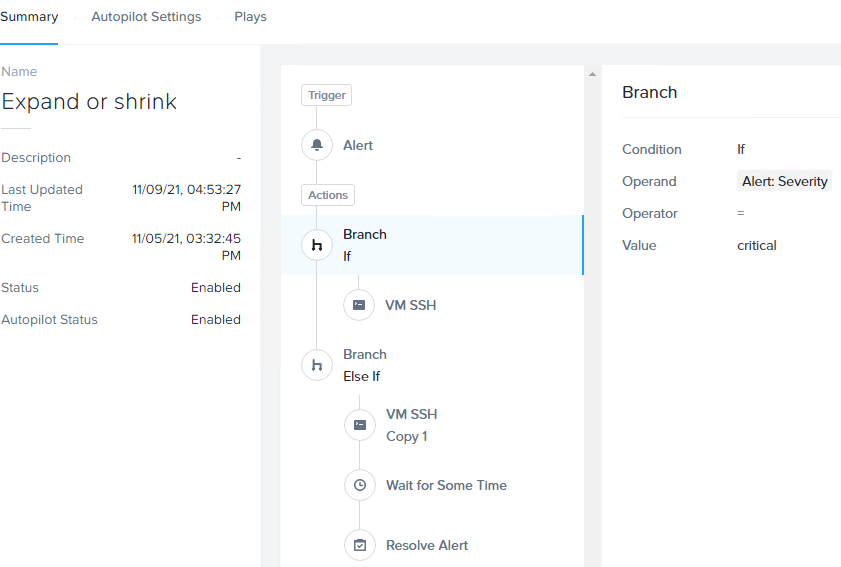
One thing to note, the spelling of warning or critical needs to be lowercase for it to work.
Once the critical workflow is triggered it will start to add a node to the cluster. Instead of adding a node to the cluster and resolving an alert we are using autopilot to keep tracking memory usage in case we need to add more nodes. The playbooks won't get triggered again on the same alert unless the alert is resolved. Using autopilot we can let it keep checking the status for us. Today with playbooks you can only have one autopilot set per playbook. We are removing nodes based on the warning criticality. With removal, we do resolve the alert after the API is made by the python script. After it's done once, we would be able to alert the trigger again causing more nodes to be removed.
I have added my scripts below. There are some other blog posts that use similar scripts that can help you walk through those. The remove node script is basically the same as the add but is also checking if there are at least 3 nodes in the cluster.
If you have any other questions, fire away! Also more coding examples on https://www.nutanix.dev/