
Nutanix CE よろず相談所が長くなってきた&Nutanix CE 2.0 がリリースされたいい機会なので、こちらに移行したいと思います。
Page 1 / 4

Userlevel 4
 +9
+9
- Nutanix Employee
- 92 replies
-
2 March 2023
CE 2.0について取り急ぎ簡単にブログにまとめましたのでご参考まで。
[2023令和最新版]Nutanix Community Edition 2.0
https://smzklab.net/2023/03/nutanix-ce2-lauched.html
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
8 May 2023
ご返信ありがとうございます。CVMのメモリサイズ指定自体は問題無さそうです。
一方で、Hugepagesに関する出力結果を見ると、Hugepagesize以外の行が軒並み0になっているので、お使いのマシンではHugepageが有効でないように見えます。有効な場合AnonHugePages, HugePages_Total, HugePages_Free, Hugetlbあたりに容量が反映されています。
これを頼りに少し掘り下げるため、virsh edit CVM名 でCVMの構成情報を開いてみると、CPU周りの設定がCE 2.0では
<cpu mode='host-passthrough' check='none'>
<numa>
<cell id='0' cpus='0-3' memory='20971520' unit='KiB' memAccess='shared'/>
</numa>
</cpu>となっていました。
https://libvirt.org/formatdomain.html
によると、以下の記載がありました。
Since 1.2.9 the optional attribute memAccess can control whether the memory is to be mapped as "shared" or "private". This is valid only for hugepages-backed memory and nvdimm modules.
よって
・memAccess='shared'という設定があることでhugepagesが要求されている
・このマシンには払い出し可能なhugepagesがない
という状態が原因でCVMが起動しなくなっているものと推測しています。
比較のためce-2020.09.16のCVMの構成情報を確認したところ、CVMのCPU設定は以下のようになっていました。
<cpu mode='host-passthrough' check='none'>
<feature policy='disable' name='spec-ctrl'/>
</cpu>memAccess='shared'(というかnuma自体の設定)がありませんでしたので、
CE 2.0のCVMのCPU設定をまるっとこの内容に書き換えることで起動可能とならないでしょうか?
同世代のマシンを持っていないので机上の推測ですが、お試し頂けますと幸いです。

お忙しい中、コメントありがとうございます。色々試したのですが、br0とbr1のブリッジ間でのAHVとCVM通信に支障がきたして、結局このパターンはNGでした。
その後、RHEL VMのKVM(ブリッジではNAT利用で問題回避)を利用して、NestedなNutanix CEの導入までは問題なくいったのですが、頻繁にCVMがダウンしたりでPrism Elementへの接続が不安定で、検証とはいえ実用に耐えない状況で、こちらの方式も諦めました。
現在、手元にESXi8.0のDVD ISOがあったので、評価版でNetstedなNutanix CEを試すところです。ただ、VMC環境のVSANを利用したデータストアは、VMCの物理ESXi上でroot権限で設定変更しないとVMFSフォーマットできないので、別のRHEL VMをNFSサーバとしてデータストア提供して試しています。また、仮想ESXiにvNICを2枚搭載させ、2枚目はRHEL VMをNATルータとして、Nutanix CEのAHVとCVMが外部ネットワークと疎通できるように回避させる予定です。
この手の環境で、Nutanix CEを利用されるケースはニッチかと思いますが、この方式で問題解決したら、また情報共有させていただこうと思います。
keroro9です。
無事、問題解決しましたので報告します。
やはり原因は、L3スイッチに適切な設定が入っていないことでした。
アライドテレシス X510系のL3スイッチでわざわざ1GインターフェースをLACPし、
かつ、CVM/AHVの稼働するVlanを指定する際に必要なconfigは下記のとおりです。
※タイプミスでchannel-groupが10になっていますがこのままにしています。
! 一台目
interface port1.0.13-1.0.16
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
channel-group 2 mode passive
lacp timeout short
! 二台目
interface port1.0.17-1.0.20
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
channel-group 10 mode passive
lacp timeout short
! 三台目
interface port1.0.21-1.0.24
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
channel-group 1 mode passive
lacp timeout short
! PortChannel設定
interface po1-2,po10
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
!
早速のレスありがとうございます!
こちらの記事は私も認識していて、Neverに設定変更していたのですが、
恐らくWebUIのセッションタイムアウト値のようでした。
再度、CVM3台の初期化デプロイを実行中で、引き続き調査してみようと思います。
問題解決しましたら、恐らくNestedな環境でNutanix CEを利用している方は、
同事象に遭遇しやすいので、情報共有させていただこうと思います。
コメントありがとうございます!
>kfujita0731さん3ノードということですがデプロイ方法(1node or 3node)、
>ESXi上の3台のcpu/memory/diskスペックはどれくらいでしょうか。
>根本解決で無いですが、cpuを盛れば30分以内で抜けられるのではないかなと思っております。
私の環境は、VMC環境の潤沢なリソースを利用したNestedな環境でのNutanix CE導入となります。
CVM/AHV各々、最終的なデプロイ時には64core/64GBmem/100GB,1.5TB,1.5TBという仮想マシンの構成のため、スペック自体は問題ないと考えております。
ただ、仮想マシンのvHDD1,2,3の大元のストレージは、VMC環境のVSANデータストアとなり、
また、VMCの諸々制約から、RHEL仮想マシンをNFSサーバとして10TBの領域をNFSデータストアとして提供し、ESXi仮想マシンにマウントさせています。
ESXi仮想マシンの仮想マシン(Nested)としてNutanix CEをデプロイさせています。
その関係で、DiskI/O周りが複数階層構成でのオーバーヘッドで性能が出ていないため、qcow2からimgへの変換処理がデフォルト30分のタイムアウトまで間に合わずエラーとなっていました。
直前のコメントにも記載させていただきましたが、VSANの仮想マシンストレージポリシーを耐障害性を犠牲にして性能向上させるポリシーに変更し、3Node構成からシンプルに1Nodeクラスタ構成にして、初めて導入に成功しました。
ただ、導入成功したのは互換性がない最新のPrism Centralではありましたが・・
現在、社内のサーバにNutanix CEをiLO経由(iLOのコンソール画面でCD/DVDをマウントできるので、そこからローカルにあるNutanix CEのISOファイルをマウント)で取り込み、起動を行っておりますが、途中で止まってしまいます。
止まってしまう箇所は下記となります。
INFO Getting AOS Version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minites if Phoenix is running from BMC
BMC経由だと数分間時間がかかるとメッセージには出ておりますが、2時間以上経過してもこのままです。解決策をご教授していただきたいです。
備考:現在、このサーバには商用版のAOS 5.x(ライセンスは既に切れているので未使用)が入っているので、一度このクラスタを削除する必要があるのかなと思っております。
こちら、解決しました。
現在、Nutanix CE2.0にPrism Centralをデプロイしたいのですが、失敗してしまいます。
調査してわかったこととして、PCのeht0に静的IPアドレスが振られていないことが判明したので
手動でIPアドレスを振り直したところ、IFのIPアドレスにはpingが成功しました。
しかし、DGWへのPINGは失敗していまします(同セグメントなのに…)。
DGWはCVMと同じアドレスとなります。また、CVMと同じサブネットマスクを使用しています。
こちら、考えられる原因としてはどういったことがございますでしょうか。
ご教授していただけると助かります。
NWの疎通さえ解消すれば、cluster --cluster_function_list="multicluster" -s <PCVMのアドレス> createが実行可能となり、PCのデプロイが完了するはずです。
PCは2022.9を使用しました。
こちら、elementで作成したVLANのID付与ミスが原因でした。
現在、社内のサーバにNutanix CEをiLO経由(iLOのコンソール画面でCD/DVDをマウントできるので、そこからローカルにあるNutanix CEのISOファイルをマウント)で取り込み、起動を行っておりますが、途中で止まってしまいます。
止まってしまう箇所は下記となります。
INFO Getting AOS Version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minites if Phoenix is running from BMC
BMC経由だと数分間時間がかかるとメッセージには出ておりますが、2時間以上経過してもこのままです。解決策をご教授していただきたいです。
備考:現在、このサーバには商用版のAOS 5.x(ライセンスは既に切れているので未使用)が入っているので、一度このクラスタを削除する必要があるのかなと思っております。
こちら、解決しました。
私も類似したトラブルでインストールが行えておりません。実施した解決策をご教示いただけますでしょうか。
Dell サーバにiDrac経由で仮想メディアをマウントしてインストールしているのですが、以下のエラーでinstallが終了している状況です。
INFO Getting AOS Version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minites if Phoenix is running from BMC
cat: /mnt/iso/images/svm/nutanix_installer_package.tar.p00: Input/output error
cat: /mnt/iso/images/svm/nutanix_installer_package.tar.p01: Input/output error
/root/phoenix/images.py の123行目で以下を実行したタイミングでのエラーかと推測しております。
shell.shell_cmd([combine_command], ttyout=True)
# ここで実行している combine_command = cat /mnt/iso/images/svm/nutanix_installer_package.tar.p0* > /mnt/svm_installer/nos.tar
試しに、上記のコマンドをssh後にホスト上で実行してみる、同様のエラーとなりました。
# cat /mnt/iso/images/svm/nutanix_installer_package.tar.p0* > /mnt/svm_installer/nos.tar cat: /mnt/iso/images/svm/nutanix_installer_package.tar.p00: Input/output error cat: /mnt/iso/images/svm/nutanix_installer_package.tar.p01: Input/output error
また、その際のdmesgは以下のようになっています。
# dmesg | tail [ 5117.728842] Buffer I/O error on dev sr0, logical block 1, async page read [ 5117.859332] sr 11:0:0:0: [sr0] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s [ 5117.859338] sr 11:0:0:0: [sr0] tag#0 Sense Key : 0x3 [current] [ 5117.859341] sr 11:0:0:0: [sr0] tag#0 ASC=0x11 ASCQ=0x0 [ 5117.859345] sr 11:0:0:0: [sr0] tag#0 CDB: opcode=0x28 28 00 00 00 00 00 00 00 02 00 [ 5117.859348] blk_update_request: critical medium error, dev sr0, sector 0 op 0x0:(READ) flags 0x0 phys_seg 2 prio class 0 [ 5117.859351] Buffer I/O error on dev sr0, logical block 0, async page read [ 5117.859354] Buffer I/O error on dev sr0, logical block 1, async page read [ 5128.216320] VFS: busy inodes on changed media sr0
以上、よろしくお願いいたします。
こちらですが、結局のところ、NWの帯域不足が原因でした。
失敗時:300GBまで帯域制限されている環境。且つ,Wi-Fi経由で通信不安定。
成功時:1GB帯域。全て有線。
私の環境も自宅からVPN経由でiDRACにアクセスしているので、安定した通信環境ではありません。
NW環境見直す or USBでインストールを試してみたいと思います。
私の環境も自宅からVPN経由でiDRACにアクセスしているので、安定した通信環境ではありません。
NW環境見直す or USBでインストールを試してみたいと思います。
VPN経由の場合、個人でWAN帯域を食いつぶさないように帯域制限かけらているはずですので、イメージのインストール失敗の原因となっていると考えられます。通信経路が全て1GB~であればおそらく問題ないはずです。USB指せるならば一番手っ取り早いです。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
28 April 2023
ちなみに、Single node clusterの自動作成に成功していると、AHVの/var/log/fistboot.logには下記のようなログが残ります。貼り付けて頂いた部分よりも前に、IPv6パースエラーの以外のメッセージはありませんでしょうか?(※投稿エラーになるので画像にしました…)
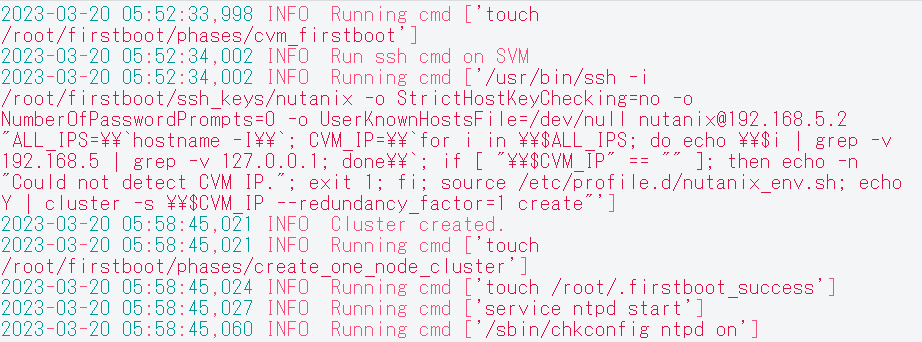
CVMでクラスタの手動作成を行い問題なく完了しました。
ありがとうございました。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
8 June 2024
デモ用環境とのことなので、HAリソースを確実に…とかを考える必要がなければ3台のスペックを均一に揃えなくても大丈夫です。
高スペックが2台あるので楽しめそうですね…!
smzksts 様
keroro9です。早々のお返事ありがとうございます。
>高スペックが2台あるので楽しめそうですね…!
はい、久々にニヤついております(笑)
iLOからログインし状況を確認していたところ、3台ともCPUも絶妙に異なっており、同環境にそろえるにはさらなる投資が必要...ちょっと無理かな~と思っていたところでしたので、情報ありがとうございます。とりあえず行けそうとわかりましたので、追加の散財はやめておきます。
(正確には14C28T*2、12C24T*2、6C6T*1の3台でした。14コアCPUはE5-2690 v4なのですが爆熱でファンがうるさいです。)
VMに関しては高スペックノードに作ればよく、各ノード96GB程度は確保できるかなあと思っているところです。足りなければ192GB程度まで増設を検討してます。
メモリ・CPUは適当な一方、クラスタ破壊テストをやりたいという観点でデータのみRF2を維持したく、データだけ偏りがないように同条件のディスクで考えておりました。つまり、#3はRF2を維持するだけのためのノードという感じになります。ついでになにか管理系のVMをデプロイするか。くらいのノリです。(この辺の認識間違っておりましたらご指摘くださいませ。)
ちょうど先ほどの書き込みを行ったあたりで待っていたサーバが到着しました。
ボーナス月ですし楽しんでいこうかと思います。
今朝再インストールしたところ、
<pae/>
</features>
<cpu mode='host-passthrough' check='none'/>
<clock offset='utc'/>
となっており、なぜかnumaの設定自体が有りませんでした。
CVMがメモリ確保できずに起動しないのは相変わらずとなります。
別にce2.0の環境はあるので、この機材は旧verで利用しようかと思います。
いろいろとご確認頂き、ありがとうございました。
NutanixCE2.0のインストールで、再起動の時(インストーラUSBを抜いた状態)に、表示された「No boot device available」が解消されました。
AHVのブートディスクの差込場所を3番から1番に変更したら、ブートできました。
アドバイスをいただき、ありがとうございました。
keroro9です。さらに追記です。各サーバの増設したNICをすべて外し、デフォルトの1Gbps*4のみの環境にそろえて再デプロイしました。その後Settings→Network Configuration→Virtual SwitchからBond typeの変更にたどり着き、Uplink Configurationにたどり着くことができました。
詳細はわからないのですが先ほどはVirtual Switch自体が空欄になってしまっていたような気もしており、いったん「NICは全部そろえとけ」ということだけ覚えておこうかなあと思っている次第です。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
4 June 2023
認証周りですと my.nutanix.com へのアクセスも必要かと思いますのでご確認頂けますでしょうか。
無事検証環境の方、構築することができました。ありがとうございました!
2点質問させてください。
・AHVのrootパスワードについて
Prism上でAHVのrootパスワードがデフォルトのものという警告が表示されており、AHVにssh接続して、「passwd root」を実行してパスワード変更を行ったのですが少し経ってからAHVに直接sshすると認証にはじかれてしまいました。
CVMからAHVにssh接続し、faillockコマンドで確認すると、CVMから数分間隔でログイン試行があり、これが原因と考えているのですが、AHVのrootパスワード変更に伴い、CVM側で何か設定変更が必要なのでしょうか。
・CVMのrootパスワードについて
AHVと間違えて1ノードCVMのrootパスワードを変更してしまったのですが、CVMのrootパスワードはデフォルトから変更してしまっても問題ございませんでしょうか。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
24 June 2024
Nutanixに関してはスイッチレスの直結構成はNGとなっています。
基本の構成としてはCVMの管理系通信もストレージ通信も同じ物理系等を使う(今は分割しようと思えばできますがデータローカリティの恩恵で通信帯域が輻輳しづらいのでそもそもあまりやらない)、また、Nutanixははじめから無停止でのスケールアウトを強く意識して設計されたプロダクトなので、そのあたりが犠牲になる直結は考慮していない、というあたりが背景かなと思います。
ちなみに、データローカリティがあるおかげで、Readに関しては1GbEでも結構速度が出ます。一方、Writeに関しては必ずノードまたぎの通信が発生するので10GbEにするとその恩恵が得られます。
VMC環境の空きESXiホスト上に、NutanixCE(AHV/CVM)を1台デプロイしたのですが、
ポートグループのセキュリティポリシー(無差別モード/偽装転送)を許可設定に変更ができないため、
Prismへの疎通が不可なのですが、何かナレッジ等はお持ちでしょうか?
デプロイした仮想マシンのvNICをもう1個追加し、AHVが利用するOpen vSwitch Bridge(br0)のアップリンクのvNICと別で、新たにCVMのvnet0が利用するOpen vSwitch Bridge(br1??)を作成し、そちらのアップリンクのvNICとして割り当てれば、何とか上記制約でも利用できるのでは?と考えているのですが・・
Broadcom問題を契機に、初めてNutanixを触ってみる段階で、
ここまでカスタマイズしてNutanixを試用するのもなんですが、
もし既知ナレッジとして、何かベストな方法があればご教示いただけますと幸いです。
AHV側のIPの9440ポート宛てをiptablesのnatテーブルとip_forward有効にて、
CVM側にInternal側の192.168.5.2:9440へフォワードする方法も試してみたのですが、うまくいかず・・
個人的には、1ノードクラスタでもいいので16コア以上、メモリは128G位の実機環境があればそれなりに評価もできるかなぁ。という感じです。上の投稿で3ノードで構築したのは、仮想マシン10台以下位なら商用並みの快適さで使えないかという意図もあります。
お求めの回答でなく申し訳ありません...。
お世話になっております。
現在、NutanixCE2.0のインストールを試みておりますが、以下のエラーが発生し、インストールが進みません。
```
ERROR SVM imaging failed with exception: Traceback (most recent call last):
File "/root/phoenix/svm.py", line 673, in image
self.deploy_files_on_cvm(platform_class)
File "/root/phoenix/svm.py", line 309, in deploy_files_on_cvm
shell.shell_cmd(['mount /dev/%s %s' % (self.boot_part, self.tmp)])
File "/root/phoenix/shell.py", line 53, in shell_cmd
raise StandardError(err_msg)
StandardError: Failed command: [mount /dev/None /mnt/tmp] with error: [mount: special device /dev/None does not exist]
out: []
INFO Imaging thread 'svm' failed with reason [None]
FATAL Imaging thread 'svm' failed with reason [None]
```
ストレージ構成は以下の通りとなっております。
```
[root@phoenix ~]# lsscsi
[4:0:0:0] disk ATA HUA723020ALA640 A870 /dev/sda
[5:0:0:0] disk ATA SPCC Solid State 9A0 /dev/sdb
[6:0:0:0] disk ATA CT500MX500SSD1 023 /dev/sdc
[10:0:0:0] cd/dvd ATEN Virtual CDROM YS0J /dev/sr0
[root@phoenix ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 477G 0 disk
sr0 11:0 1 5.2G 0 rom /mnt/iso
sdc 8:32 0 465.8G 0 disk
sda 8:0 0 1.8T 0 disk
```
sdaにはData、sdbにはHypervisor、sdcにはCVMをインストールする想定となっております。
また、インストーラーの起動時に自動的にインストール先が指定されており、
自動的に指定された場合は、sdaにはData、sdbにはCVM、sdcにはHypervisorという
構成となり、この構成の場合はエラーが発生せず、インストールが完了します。
情報をお持ちの方がいれば、ご教示いただけると幸いです。
sda 8:0 0 1.8T 0 disk DATA
sdb 8:16 0 477G 0 disk AHV
sdc 8:32 0 465.8G 0 disk CVM
AHVは一番小さくしなくてはいけないという問題じゃないですかね。
redditでgruftさんが書いているのを見ました。
あと関係ないと思いますがportの順番も見ているそうなのでDATAは一番下に持っていったほうが良いかもしれません。
Page 1 / 4
Reply
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.