
I deployed a fully functional NKP management cluster without Prism Central — not because I lacked hardware, but because I'm building something different: a natural language control plane for NKP powered by AI agents and the Model Context Protocol (MCP). The goal is to replace point-and-click infrastructure management with conversational orchestration. Given yesterday's AMD + Nutanix $250M partnership announcement targeting agentic AI on NKP, I believe this direction is more relevant than ever.
The Problem I'm Solving
As a telecommunications engineer who has spent 15+ years deploying infrastructure across Latin America, I've observed a consistent pattern: the bottleneck is never the technology — it's the operational complexity.
Prism Central is excellent for what it does. But when I think about the next generation of infrastructure management — especially for LATAM enterprises that need to operate NKP clusters at the edge, in air-gapped government environments, and across distributed telco sites — I ask myself: what if the operator didn't need a GUI at all?
What if a platform engineer could simply say:
"Deploy an NKP management cluster with 3 control plane nodes and 4 workers, Cilium CNI, and the full observability stack. Then create a workspace called 'telco-prod' with a project for our 5G core network functions."
And the system would do it. Report progress. Handle errors. Explain what it did and why.
That's what I'm building.
Why NKP is the Perfect Foundation
NKP's architecture is uniquely suited for this approach, and here's why:
1. Pure Upstream Kubernetes + CAPI NKP doesn't wrap Kubernetes in a proprietary API. It uses Cluster API natively. This means every operation — cluster creation, scaling, upgrades, deletion — is a Kubernetes resource operation. Kubernetes resources are perfectly suited for programmatic, API-driven interaction by AI agents.
2. FluxCD GitOps Built-In Every configuration change in NKP flows through FluxCD. This gives us an auditable, version-controlled pipeline that AI agents can both read and write to. The agent doesn't need special access — it works through the same Git-based workflow that NKP already uses.
3. Open-Source Application Stack Prometheus, Grafana, Loki, Cilium, Traefik, Gatekeeper — these all expose standard APIs. An AI agent can query Prometheus for cluster health, check Gatekeeper for policy violations, and inspect Traefik for ingress configuration, all through well-documented interfaces.
4. Multi-Platform Support NKP runs on Nutanix AHV, VMware, bare metal, AWS, Azure, and more. My agentic control plane is infrastructure-agnostic by design — just like NKP itself.
What I Built
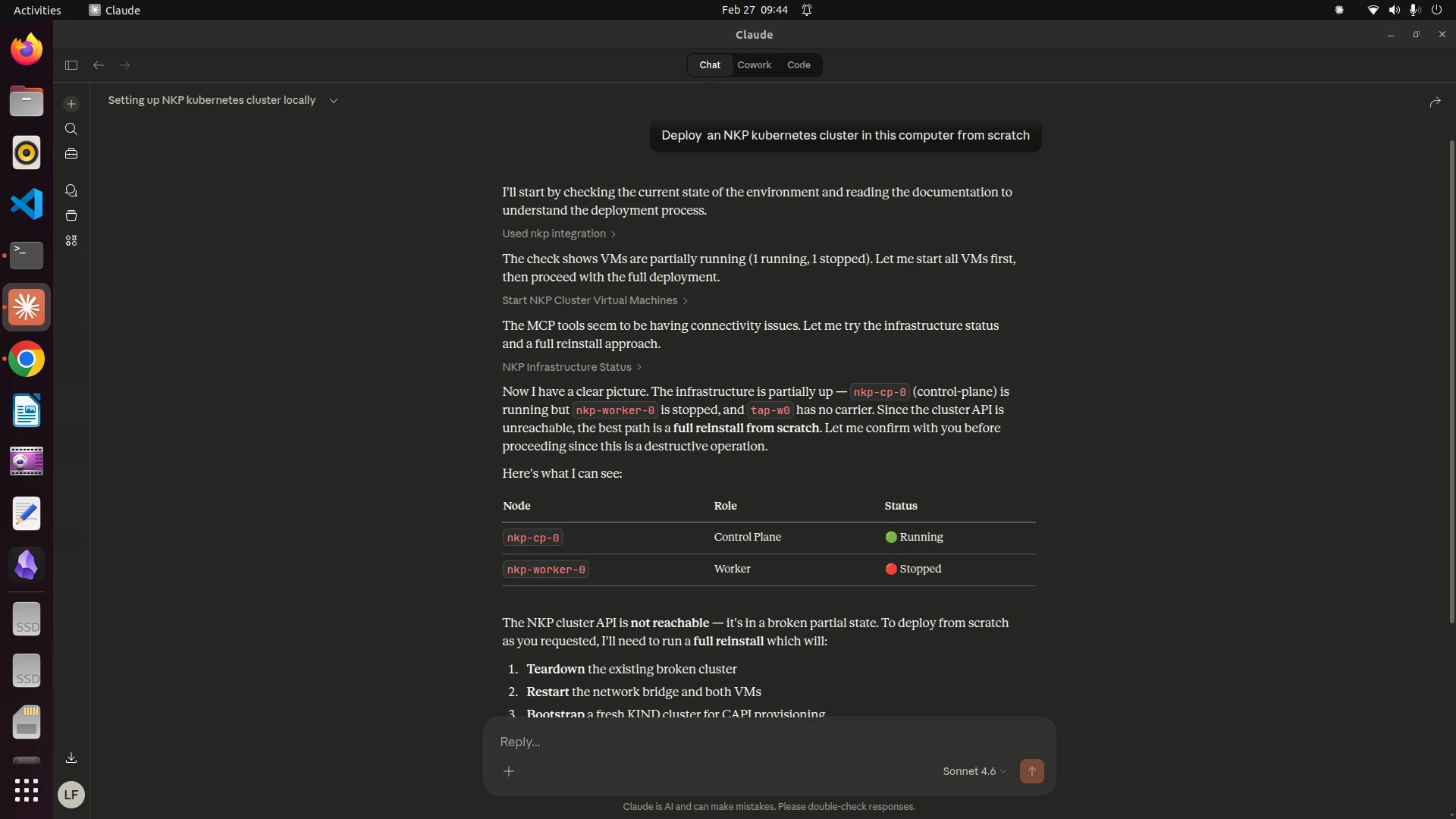
I deployed a fully functional NKP v2.17 management cluster using CAPI's preprovisioned provider. The architecture runs CIS-hardened OS images (Rocky Linux 9.6 for control plane, Ubuntu 24.04 for workers), managed through systemd service units for lifecycle automation, cloud-init provisioning, and Linux bridge networking with NAT. The cluster runs Konvoy + Kommander with the full platform application stack: Calico for CNI, the observability suite, Traefik for ingress, cert-manager, MetalLB, Gatekeeper, and FluxCD for GitOps.
The deployment accelerates the standard NKP workflow by eliminating the dependency on Prism Central for initial cluster provisioning — focusing instead on the Kubernetes-native control plane that NKP already provides through CAPI. This isn't a shortcut; it's a deliberate architectural decision. Prism Central adds value for VM lifecycle management on AHV, but NKP's power comes from Cluster API and Kommander, which are fully functional without it.
On top of this cluster, I built MCP (Model Context Protocol) servers — 15 tools that expose NKP operations as capabilities that AI models can invoke through natural language. The MCP servers provide:
- Cluster Lifecycle Management — Health checks, node status, component readiness through conversational commands
- CAPI Status — Inspect Cluster API clusters, machines, control planes without navigating Kommander UI
- Workspace & Project Management — Create NKP workspaces and projects, assign clusters, configure RBAC — all via natural language
- Observability Queries — Ask questions like "which pods are failing in the telco-prod workspace?" and get filtered, contextual answers
- GitOps Pipeline Status — Check FluxCD Kustomizations, HelmReleases, and source reconciliation in one query
- Infrastructure Visibility — VM status, disk usage, network topology, deployment logs — the full picture below Kubernetes
- Configuration Access — Read cluster configs, cloud-init templates, preprovisioned inventory directly through conversation
- Documentation Search — A complete Obsidian vault with 10 documentation sections, searchable through the agent
- Full Deployment Reports — A single command generates a comprehensive assessment suitable for customer presentation
The key insight: Prism Central provides a visual abstraction over infrastructure. My MCP agents provide a conversational abstraction. Both serve the same purpose — making complex operations accessible — but the conversational approach scales differently and enables automation patterns that GUIs cannot.
Alignment with Nutanix Strategic Direction
On February 25, 2026, AMD and Nutanix announced a $250M strategic partnership to build an open, full-stack AI infrastructure platform for agentic AI applications on NKP. The press release specifically mentions:
- "Enterprise AI agents, multimodel inference services, and industry-specific intelligent applications"
- "Unified lifecycle management via Nutanix Enterprise AI"
- "Open-source and commercial AI models without dependency on vertically integrated AI stacks"
This is exactly the direction I've been building toward. The agentic control plane I've developed is a concrete, working prototype of the kind of intelligent infrastructure management that the AMD-Nutanix partnership aims to productize.
Why This Matters for LATAM
Latin America has specific challenges that make agentic AI infrastructure management particularly valuable:
Skills Gap: There aren't enough Kubernetes experts in LATAM to serve every enterprise that needs NKP. A natural language interface dramatically lowers the barrier to entry for infrastructure operations.
Distributed Edge: Telcos deploying private 5G networks need NKP at dozens of edge sites. You can't have a Prism Central expert at every location. But you can have an AI agent accessible from anywhere.
Government Compliance: LATAM governments (Colombia's MinTIC, Brazil's ANATEL) increasingly require data sovereignty. An on-premises AI agent running a local SLM (Small Language Model) satisfies sovereignty requirements while providing intelligent operations.
Cost Optimization: For organizations that can't justify the full NCI + Prism Central stack at every site, NKP on bare metal or lightweight infrastructure with an AI control plane provides enterprise-grade operations at a fraction of the cost.
What's Next
I'm presenting related work at KubeCon EU 2026 in Amsterdam (Cloud Native Telco Day) and OpenInfra Colombia in May 2026. The next phases include:
- Inference on NKP — Deploying a local SLM (Phi-4-mini or Llama 3.2) as a Kubernetes workload on NKP itself, creating a self-managing cluster that hosts its own AI brain
- Telco-Specific Agents — Specialized agents for 3GPP network function lifecycle management on NKP
- Multi-Cluster Fleet Operations — Extending the MCP agents to manage fleets of NKP clusters through Kommander's API
- Nutanix Enterprise AI Integration — When NAI becomes available for this architecture, integrating the inference endpoint with the native model management capabilities
Call to Action
I'd love to hear from the Nutanix community:
- Has anyone else explored AI-driven NKP operations?
- What are the most painful Day 2 operations that you'd want to automate through natural language?
- For those working with LATAM customers — what operational challenges would benefit most from this approach?
If you're interested in collaborating or want to see a demo, reach out. I'm also organizing Colombia OpenInfra User Group in May at Bogota and would welcome Nutanix community members to present. More information in the following link: https://www.meetup.com/colombia-openinfra-user-group/events/313396409/?utm_medium=referral&utm_campaign=share-btn_savedevents_share_modal&utm_source=link&utm_version=v2&member_id=389775349

