


This post was authored by Jesse Gonzalez — Cloud Native & AI Solutions Architect, Nutanix
This article is the second part of a blog series exploring how modern infrastructure solutions address the computational and memory challenges of serving large language models (LLMs) with massive context lengths. Specifically, it details the synergistic architecture of LMCache (an open-source Key-Value Cache manager), Nutanix Files (a high-performance, scale-out file storage solution), and NVIDIA GPUDirect Storage (GDS).
Part 1, Context Overload, of the GPU Kind, identified the core scaling problem: increasing LLM context windows linearly inflate the Key-Value (KV) cache. This excessive KV cache consumes High Bandwidth Memory (HBM) on the GPU, causing "Context Overload"- low GPU utilization, restricted batch sizes, and high inference costs. Part 1 concluded that an efficient solution to offload and manage the KV cache outside of GPU HBM is crucial for scaling.
The rapid evolution of Large Language Models (LLMs) has been accompanied by a relentless expansion of their context window capabilities. While a larger context window enables richer, more complex interactions and better reasoning, it simultaneously presents a massive infrastructure challenge: managing the Key-Value (KV) cache. The KV cache—which stores the intermediate key and value vectors generated during the prefill and decoding phases—grows linearly with the context length, quickly consuming precious and costly High Bandwidth Memory (HBM) on the GPU. This "Context Overload" leads to low GPU utilization, constrained batch sizes, and skyrocketing inference costs.
This post, the second in our series, moves beyond identifying the problem to presenting a powerful, integrated solution. We will delve into the technical mechanics of a three-part architecture—LMCache, Nutanix Files Storage, and NVIDIA GPUDirect Storage (GDS)—that effectively tames the challenges of scaling LLM inference. By transforming the KV cache from a GPU-confined bottleneck into a manageable, persistent, and sharable asset on high-performance remote storage, organizations can unlock unprecedented efficiency and scale for their most demanding AI workloads.
Introducing LMCache: The KV Cache Manager
LMCache is an open-source library that acts as a sophisticated Key-Value (KV) Cache manager, designed specifically to tackle the memory and performance bottlenecks of large-context LLM inference. It integrates directly with popular serving frameworks like vLLM, allowing developers to implement advanced caching strategies that go beyond simple on-GPU storage.
LMCache introduces the ability to offload and share KV caches across multiple tiers of storage (GPU, CPU, local NVMe, or remote file storage), effectively transforming the KV cache from a GPU-confined resource into a persistent, sharable, and highly optimized asset.
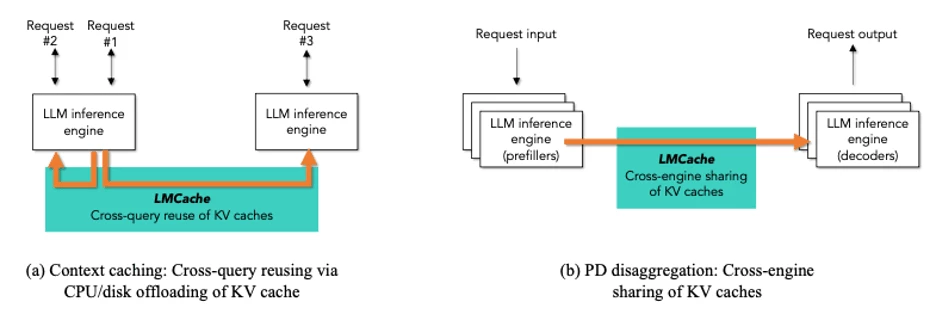
Key Capabilities of LMCache:
- Cache Offloading and Swapping: LMCache intelligently manages the lifecycle of KV caches. When a cache becomes inactive or "cold," it can be efficiently swapped out from precious GPU memory to a lower-cost tier, such as system DRAM or high-speed remote storage. When the cache is needed again, it's quickly swapped back in, minimizing the performance penalty of cache eviction and recomputation.
- Cache Sharing and Reuse: In scenarios like multi-turn conversations or similar user queries, LMCache enables the reuse of cached prefixes. Instead of re-running the heavy prefill phase for the common prefix, the pre-computed cache segment is loaded and shared across different inference requests, significantly boosting TTFT and reducing compute load.
- Integration with High-Speed I/O: LMCache is designed to leverage high-throughput, low-latency data paths, making it an ideal partner for technologies like NVIDIA GPUDirect Storage (GDS) and NFSoRDMA with Nutanix Files Storage. This integration is crucial when offloading caches to remote storage so that the I/O operation doesn't become the new performance bottleneck.
By providing a unified and optimized framework for KV cache management, LMCache, when coupled with the high-performance, distributed storage capabilities of Nutanix Files Storage, allows organizations to maintain large context lengths, increase GPU concurrency, and reduce overall inference costs—all without resorting to expensive, underutilized GPU overprovisioning.
Making the Case for Offloading to Remote Storage
While offloading to CPU or NVMe is often simpler from an administrative overhead perspective, it is often limited to the capacity of a single machine, which can be a bottleneck for large-scale deployments or workloads with very large context lengths.
Offloading to remote storage can unlock additional benefits such as:
- Scalability: Offloading KV cache to remote storage allows scaling beyond the limits of a single machine’s CPU memory or NVMe capacity.
- Cache Persistence: Remote storage enables KV caches to persist beyond the lifetime of a single inference node, allowing reuse across multiple nodes and sessions.
- Cost Efficiency: Using shared remote storage can be more cost-effective than provisioning large amounts of local CPU memory or NVMe for each inference node.
- Multi-Node Sharing: Multiple inference nodes can share the same KV cache stored on remote storage, improving cache hit rates and reducing redundant computations.
- Fault Tolerance: Remote storage can provide redundancy and fault tolerance, ensuring KV caches are not lost if an inference node fails.
LMCache can leverage remote backend storage systems to offload KV cache that support NVIDIA GPU Direct Storage (GDS) directly or as a backend connector using the NVIDIA NIXL plugin. Both methods are supported when using Nutanix Files Storage.
NVIDIA NIXL is a ultra-fast communication library that allows LMCache to dynamically select the fastest available data path between GPUs, CPUs and storage - ideally when using solutions that leverage NVLink, RDMA-capable NICs and GPU Direct Storage - which when combined, can offer unmatched bandwidth and latency across devices.
To achieve the values of these benefits, the transferring of KV Cache data between remote access tiers requires a low-latency, high-bandwidth distributed storage solution that allows for both reading and writing of large volumes of content. Leveraging both Nutanix Files Storage and NVIDIA GPUDirect Storage (GDS) can provide the necessary performance needed to make remote offloading viable.
Deciding When to Move Your KV Cache to Remote Storage
When deciding whether to offload KV cache to remote storage, consider the following scenarios:
- If you ARE: Running large language models (LLMs) that exceed local GPU, CPU RAM or NVMe disk capacity needed to save all the KV cache on the resources available to a single inferencing node.
- If you HAVE: Many user prompt Requests that share the same prefix, across multiple LLM Models
- If you NEED: To Run multiple LLM models or Run multiple instances of a LLM model across a pool of inferencing nodes.
Then consider offloading the KV cache to Remote Storage - such as Nutanix Files Storage - where you can expect:
- Reduced GPU memory usage, enabling the deployment of larger models on existing hardware.
- Improved throughput for workloads with shared prefixes, as the offloaded KV cache can be reused.
- Reduced Time-to-First-Token (TTFT) for requests with shared prefixes, as the prefix KV cache is already available in CPU memory.
To make remote offload viable, storage must deliver GPU-speed I/O. That’s where Nutanix Files Storage with NFS v5.2 RDMA and NVIDIA GPUDirect Storage (GDS) come in.
Nutanix Files Storage: The Foundation for GPU-Accelerated Remote KV Caching
To effectively offload KV caches to remote storage, the underlying file system must provide high-throughput, low-latency access that can keep up with the demands of GPU workloads.
NVIDIA GPUDirect Storage (GDS) establishes a direct DMA path between GPU memory and storage devices, bypassing CPU involvement. Combined with Remote Direct Memory Access (RDMA) — specifically NFS-over-RDMA (NFSoRDMA)—this architecture achieves true zero-copy transfers.
Nutanix Files Storage is a software-defined, scale-out file storage solution that provides high-performance, scalable, and resilient file services for enterprise workloads. It is designed to run on Nutanix's hyper-converged infrastructure (HCI) platform, which combines compute, storage, and networking resources into a single integrated system.
Nutanix partners with NVIDIA on a number of AI initiatives, which often include performing rigorous testing and certification efforts across their respective platforms.
Through these learnings, Nutanix Files Storage provides a specialized file server profile optimized for high-throughput, low-latency performance requirements that is exclusively designed for AI workloads. For additional details, see Nutanix Files Performance Profile for AI Workloads.
When combined with NVIDIA GPUDirect Storage (GDS), Nutanix Files Storage can deliver the high-throughput, low-latency performance needed to support remote KV cache offloading for LLM inference workloads.
Some of the key benefits of using Nutanix Files Storage with GDS for KV cache offloading include:
- Zero-Copy Data Path: GDS allows GPUs to perform direct DMA transfers between device memory and Nutanix Files Storage, bypassing CPU memory and kernel bottlenecks.
- RDMA-Accelerated Throughput: Nutanix Files Storage over RoCEv2 provides microsecond-scale latency and multi-10 GB/s bandwidth — ideal for LMCache’s batched 1–16 MB chunk transfers.
- Enterprise-Ready Integration: Nutanix Files Storage offers snapshots, replication, and security features, keeping KV cache data protected.
This eliminates the need for bespoke object stores or external caching appliances. The result: LMCache treats Nutanix Files Storage as a “cold tier” of GPU memory — fully transparent to inference pipelines.
Data Flow and Operations
LMCache effectively manages Key-Value (KV) cache chunks generated by the model on the GPU through the following operations:
- GPU Memory Conservation: Excess KV caches are offloaded from the GPU to CPU DRAM.
- Asynchronous Commits: KV caches residing on the CPU are asynchronously written to disk or remote storage, governed by an LRU eviction policy.
- Prefetching: Frequently accessed ("hot") KV caches are prefetched from disk or remote storage back to the CPU as needed.
- On-Demand Reuse: Cached segments can be reused by transferring them from the CPU back to the GPU on demand
(Reference: https://docs.lmcache.ai/developer_guide/architecture.html)
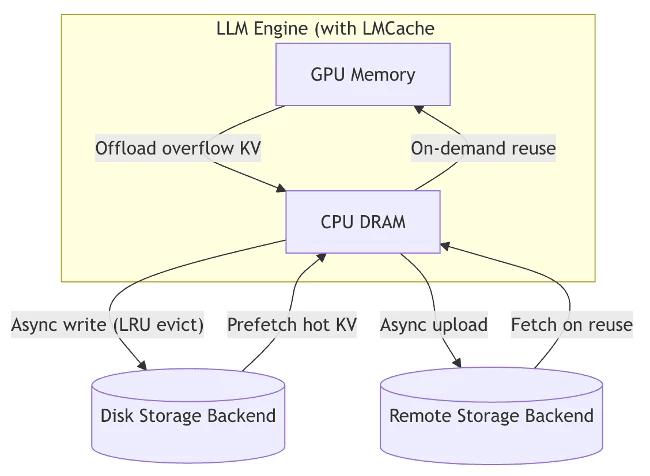
This architecture enables LMCache to significantly reduce prefill delays and GPU memory pressure while maintaining high performance through intelligent cache management.
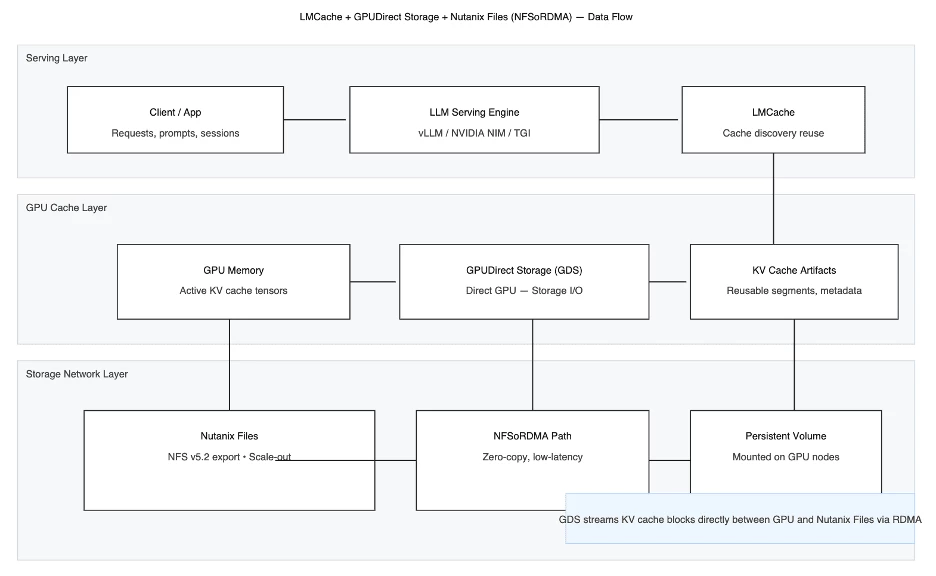
LMCache + Nutanix Files Storage + GDS: End-to-End Workflow
The true power of this solution lies in the seamless, high-speed integration of LMCache, Nutanix Files Storage, and NVIDIA GDS.
This section illustrates the step-by-step data path, demonstrating how the KV cache is managed, offloaded, and reused with GPU-accelerated I/O, transforming remote storage into an effective extension of GPU memory.
- Inference request arrives: The serving engine (e.g., vLLM) allocates GPU memory for token processing.
- LMCache intercepts KV operations: It identifies reusable segments of the cache (e.g., shared context or history).
- Offload to remote storage: Through GDS, KV cache data streams directly from GPU memory to Nutanix Files Storage — bypassing the CPU.
- NFSoRDMA transport: RDMA (Remote Direct Memory Access) eliminates TCP overhead, delivering near-zero-copy transfers between GPU and NFS storage.
- Cache reuse: Subsequent sessions can instantly reload the cache via the same GDS path, dramatically reducing prefill latency and GPU load.
In the next part of this series, we’ll see the performance profile of this unified solution in action, and how this architecture delivers significant advantages in terms of throughput, latency, and operational cost efficiency for large-scale LLM inference.
The "Context Overload" challenge—where expanding LLM context windows place an unsustainable burden on costly GPU memory—is a critical bottleneck for scaling modern AI applications. This article has detailed a potent, integrated solution that addresses this problem head-on: the synergistic architecture of LMCache, Nutanix Files Storage, and NVIDIA GPUDirect Storage (GDS).
By intelligently transforming the Key-Value (KV) cache from a GPU-confined liability into a persistent, shared asset on high-performance remote storage, this solution unlocks significant efficiencies. LMCache manages the cache lifecycle, swapping inactive segments out; Nutanix Files Storage provides the scalable, reliable, and performance-optimized storage foundation; and the combination of GDS and NFSoRDMA ensures that the remote I/O is fast enough to act as a seamless "cold tier" of GPU memory.
This architecture can deliver tangible benefits: it reduces GPU memory pressure, enables the use of larger context lengths and batch sizes, increases model concurrency, and ultimately provides opportunity to drive down the total cost of ownership for large-scale LLM inference deployments.
What's Next: Performance Metrics and Real-World Impact
In Part 3 - the final part of this series, we will move from architecture to action. Part 3 will showcase a real-world case study, providing concrete performance metrics and comparative data. We will demonstrate the gains in throughput, reductions in Time-to-First-Token (TTFT), exemplifying cost savings that may be achieved when implementing LMCache with Nutanix Files Storage and NVIDIA GDS compared to traditional, GPU-only KV cache management. Stay tuned to see the performance profile of this unified solution in action.
References / Further Reading
- LMCache GitHub
- NVIDIA GPUDirect Storage
- Nutanix Files Product Page
- Nutanix Files Performance Profile for AI Workloads
- Nutanix Kubernetes Platform
- vLLM Project
- HackerNoon: Optimizing LLM Performance with LM Cache
- NVIDIA Dynamo Blog
- LLM Inference VRAM & GPU Requirement Calculator
- KV Caching Explained: Optimizing Transformer Inference Efficiency
©2026 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product and service names mentioned are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned are for identification purposes only and may be the trademarks of their respective holder(s). This content reflects an experiment in a test environment. Results, benefits, savings, or other outcomes described depend on a variety of factors including use case, individual requirements, and operating environments, and this publication should not be construed as a promise or obligation to deliver specific outcomes.