


This post was authored by Jesse Gonzalez — Cloud Native & AI Solutions Architect, Nutanix
Today’s real-world AI applications — from copilots to chatbots — rely on large context lengths and long persistent conversation history to deliver natural, human-like interactions. But those expanding context lengths are inflating GPU memory needs and inference costs.
The escalating costs and performance bottlenecks associated with Large Language Model (LLM) inference at scale present a significant challenge for organizations deploying AI-powered applications. Context windows, which store the history of a conversation or query, are a primary driver of these high costs, as they consume vast amounts of high-speed GPU memory and require repeated, costly re-computation for every token generated. This is the first post in a technical deep-dive blog series exploring a powerful solution to this problem.
In this first post of the series, we will unveil the underlying challenge and introduce a powerful solution that effectively addresses these issues, with the potential to dramatically lower operational expenditure while simultaneously boosting inference throughput, reducing per-request latency, and delivering a superior end-user experience.
In the next part, we will go deeper into the three key technologies that enable this solution: LMCache, a cutting-edge open-source KV (Key-Value) cache offload mechanism designed specifically for LLM context, Nutanix Files Storage, a massively scalable, high-performance distributed file storage platform, and NVIDIA GPUDirect Storage (GDS), a technology that enables a direct data path between GPU memory and storage.
Lastly, we will detail the performance results and architecture in the subsequent parts of the series, showing how the integration of LMCache and Nutanix Files Storage, accelerated by GDS, enables organizations to:
- Tame GPU Memory Costs: By offloading the extensive and static context KV cache from expensive, scarce GPU High Bandwidth Memory (HBM) to high-performance, cost-effective storage provided by Nutanix Files Storage, organizations can serve the same number of requests with fewer GPUs or, more commonly, increase the batch size and concurrent users on existing hardware.
- Boost Inference Throughput: The ability to store and rapidly retrieve large context windows from LMCache via GDS and NFSoRDMA can significantly reduce the re-computation overhead, allowing the system to process more tokens per second.
- Lower Latency and Improve User Experience: With context available instantly from the external cache, the time-to-first-token can be reduced, leading to fast response times and a more fluid, interactive experience for users of LLM-powered applications.
Large language models (LLMs) are transforming enterprise AI workloads, but scaling them efficiently remains one of the biggest infrastructure challenges — especially when GPU memory becomes the limiting factor.
For each token processed by an LLM, the model generates a “memory” in the key–value (KV) cache as a means of storing an intermediate state (i.e., conversation history) for each inferencing request.
A token is a chunk of text that the model processes as a single unit. It can be as short as one character or as long as one word.
For smaller LLM models, this cache is often manageable, but for larger LLM models or scenarios that require longer and larger prompts, the KV cache can balloon to tens of gigabytes per session.
For example, moderately sized LLM models like Llama-3 70B or Mixtral 8×7B with a context length of 32K tokens can easily generate KV cache sizes exceeding 20–40 GB per user session.
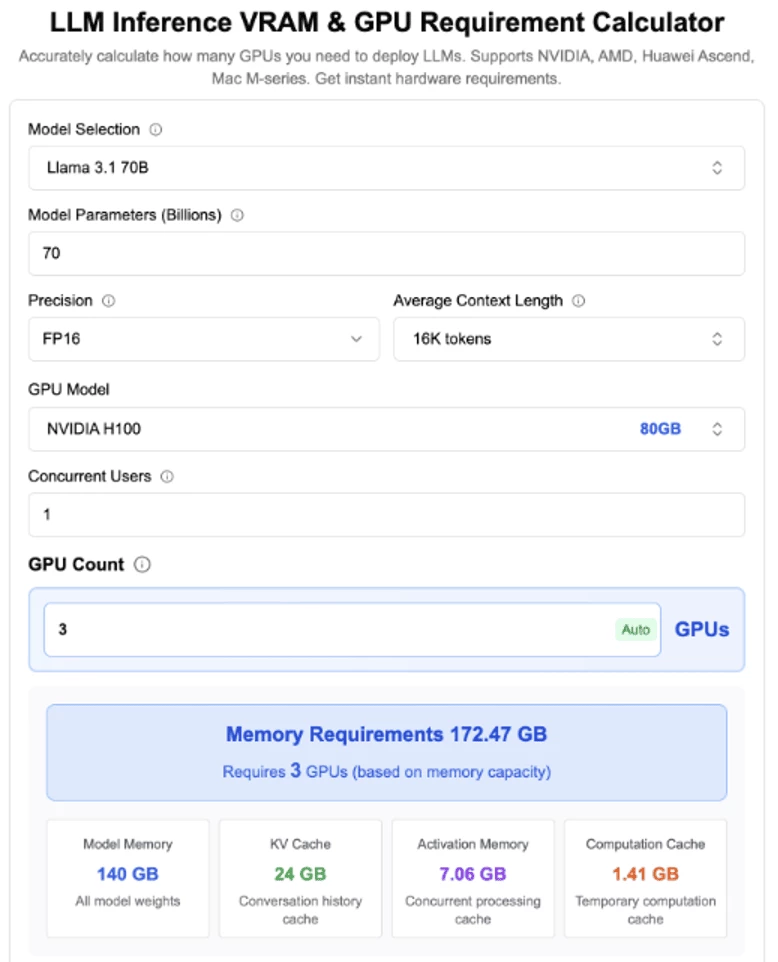
When multiple users or sessions are active, the cumulative KV cache size can quickly exhaust the available GPU memory capacity, causing each future inferencing request needing to recompute the cache. Recomputing this cache for every inference wastes GPU cycles and inflates time-to-first-token (TTFT), which increases latency, and limits concurrency.
Using the same example as above, to increase GPU capacity to support an additional 20 concurrent users would not only require over ~490 GB of GPU memory, but also need to scale up beyond the physical limits of a single physical host with 8xH100 GPUs!!!
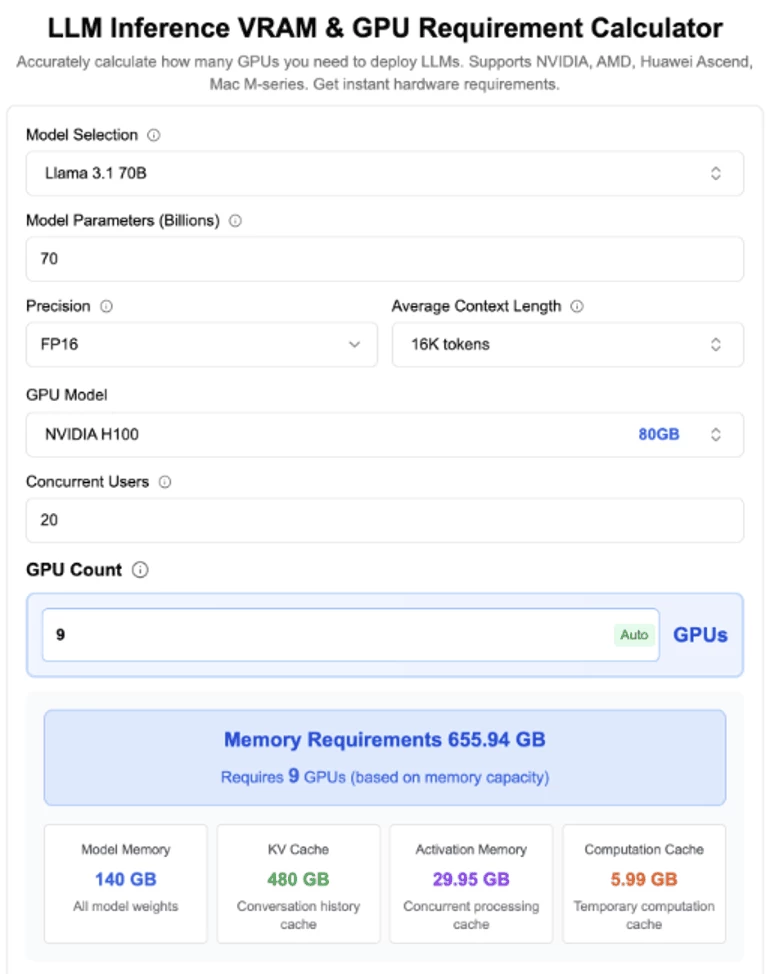
To address this challenge, many organizations resort to throwing more GPUs at the problem — but this is neither cost-effective nor scalable.
That’s where LMCache and GPUDirect Storage (GDS) come in — and when combined with NFS shared storage solutions like Nutanix Files Storage, they unlock a high-performance path for cache persistence, cache sharing, and cache reuse across heterogeneous inference workloads.
Smarter caching, not just faster GPUs, will define next-generation inference.
In this post, we’ll explore how this integration can accelerate inference performance while optimizing cost and scalability for enterprise deployments. As you continue reading, some of the key takeaways will include:
- Understand the challenges of scaling LLM inference with large context lengths and KV caches.
- Learn how LMCache enables efficient offloading and sharing of KV caches.
- Discover how Nutanix Files Storage and GPUDirect Storage facilitate high-throughput, low-latency cache access.
- See real-world performance improvements and cost savings from this integrated solution.
The Rise of Context Lengths and the KV Cache Challenge
Ever wondered why your LLM inferencing requests seem ridiculously slow - even on the most powerful (and notably expensive) GPUs? Well, you're not alone, and no - it's not because your GPU is melting under the pressure of all those tokens!

Much of this slowness can be linked to the growing demand for LLM models that can support significantly larger context windows needed by most modern Generative AI applications.
Having both larger context lengths and context windows allow models to reason over entire documents, maintain conversation memory, and generate more coherent and contextually relevant responses, especially for tasks involving long documents or multi-turn conversations.
But there is a tradeoff - this explosive growth in context windows has led to a need for massive Key–Value (KV) Cache sizes that often exceed the available GPU memory capacity - leading to various scalability and performance bottlenecks.
What were some of the trends that led to this explosion?
- Longer User Conversation Histories: As users engage more frequently with LLMs, their ongoing interactions generate longer histories — each one added to future prompts as part of the model’s contextual input.
- Multimodal Inputs: Modern LLMs now process multimodal data like images and videos, which are converted into extensive token sequences before entering the model.
- Prompt Engineering Templates: The latest generation of LLMs supports expanded context windows, enabling prompt engineers to include far more tokens within a single request.
- Reasoning Models: Models that spend more time "Thinking" tend to produce extremely lengthy outputs, which are often fed back as inputs for later steps in the same workflow.
What impact do these trends have on the KV cache?
- Increased average context length per request, which in turn inflates the size of the KV cache needed to store intermediate attention states.
- Since the KV cache grows linearly with context length, even modest increases can quickly exhaust the available GPU memory capacity, causing the GPU to become both the bottleneck and limiting factor to overall system responsiveness and throughput.
Once KV cache capacity has been reached, the KV cache eviction process is triggered causing the recomputation of all intermediate attention data, leading to:
- Increased Latency due to longer prefill times, impacting Time to First Token (TTFT)
- Lowered Concurrency as GPUs become saturated handling cache recomputations
- Increased Costs due to inefficient GPU utilization
Effective management of the KV cache is therefore critical to unlocking the full potential of large-context LLMs in production environments.
So, we've mentioned both context window and context length several times already, but what exactly do these terms mean — and how do they differ?
Demystifying Context Window vs. Context Length
In large language model (LLM) terminology, context length and context window are closely related, but they describe different facets of how a model processes information, especially in relation to token limits.
Here is TLDR;
- The context window sets the upper limit.
- The context length is the current usage within that limit.
Otherwise, here is a more detailed explanation:
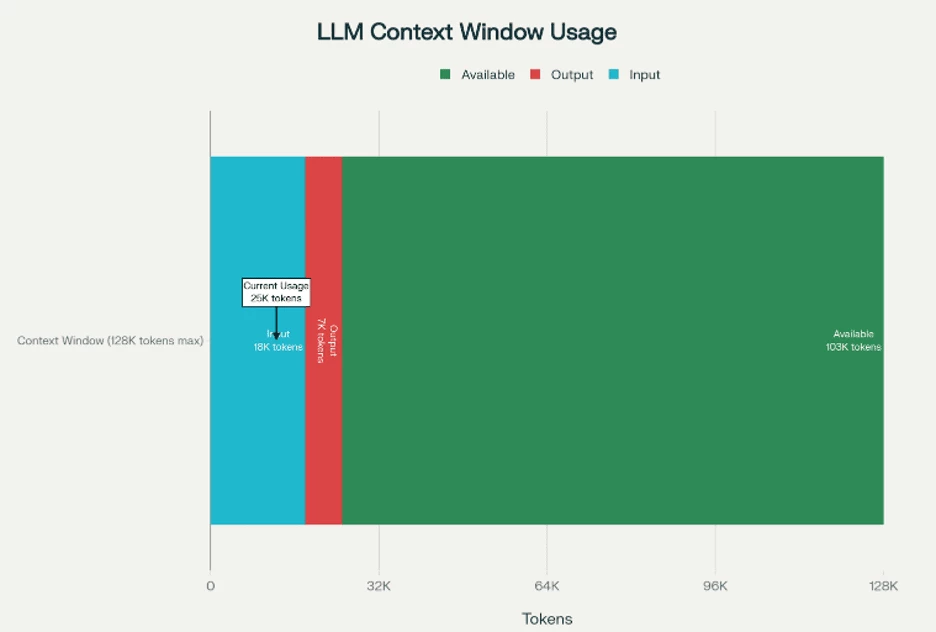
The context window is a fixed (model-dependent) number that defines the maximum number of tokens a model can process (or “see”) at one time when generating a response. It defines the model’s working memory — the range of text (input plus output) that remains “in scope” during a single inference.
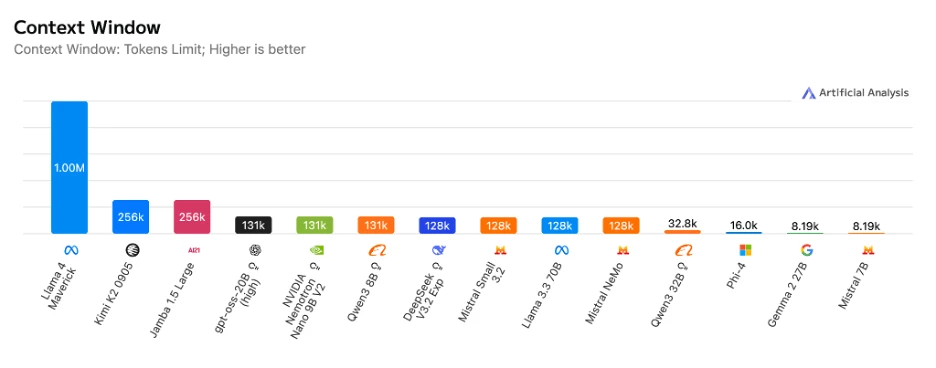
Here we see some of the most popular LLM models that already support context windows of 32K, 128K or even 1 million tokens — a massive leap from the original 4K or 8K token limits seen just a few years ago!
The context length, on the other hand, is a variable (prompt-dependent) number that defines the actual amount of text (measured in tokens) currently being used or consumed within the max context window of a model. The size of context length is dynamic and can change based on the total input size, conversation history and/or documents actively being used within the current prompt.
The context length will never exceed the context window. (i.e., A model with a context window of 8k cannot process current conversation that has context length 16k tokens).
Having a clear understanding of both context window and context length is crucial for optimizing LLM deployments, as it directly impacts model selection, infrastructure planning, and user experience design, all of which are essential for building effective Generative AI applications.
Understanding the KV Cache Challenge
In traditional LLM serving scenarios, every inference request is divided into two phases:
- The Prefill Phase – in this phase the model processes the entire input prompt, converting it into embeddings and building the initial KV cache.
- The prefill phase is compute-heavy, requiring significant GPU resources to process large input prompts and build the KV cache.
- The Decode Phase – in this phase model generates output one token at a time, reusing the KV cache to preserve context. This stage is sequential and memory-bound.
- In contrast, the decode phase is memory-bound, relying heavily on fast access to the KV cache to generate tokens sequentially.
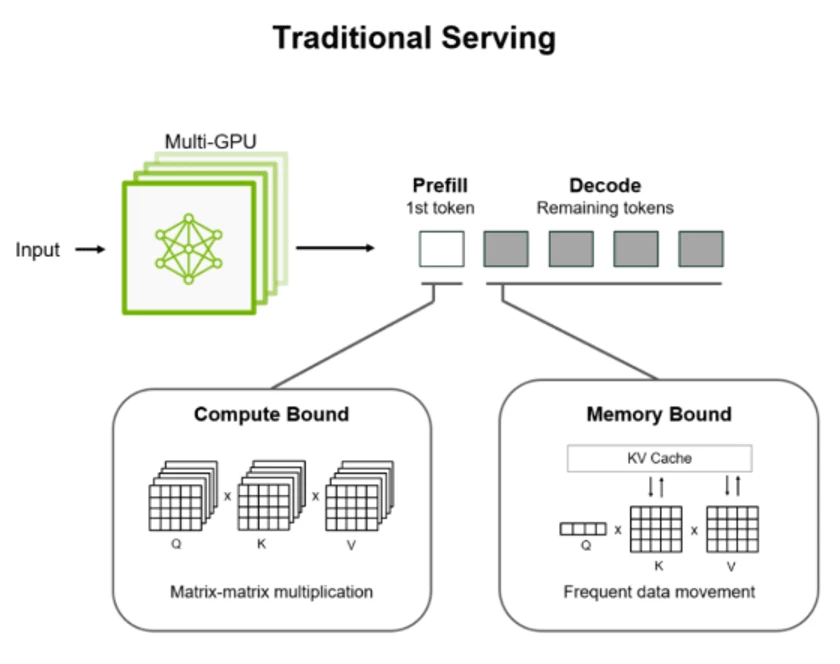
The challenge is - By default, most LLM inferencing engines would tightly couple both of these phases on the same GPU, despite their vastly different resource requirements.
By running both phases on the same GPU often, the prefill phase could monopolize resources that would simultaneously be needed by the decode phase, causing unexpected resource contention and starvation and resulting in a user experience that is quite suboptimal.
This is where KV caching comes into play.
The Key–Value (KV) Cache is a core data structure that stores intermediate attention matrices during LLM inference directly on the GPU's memory. By caching these Key (K) and Value (V) tensors, the model avoids recomputing attention states for every newly generated token, dramatically improving efficiency.
This is done by skipping the heavy prefill phase and loading a pre-computed KV cache, allowing the model to deliver the first token almost instantly. Allowing rapid results from the time to receiving that first token transforms the user experience - from an initial pause to a response that feels immediate and fluid.
To better understand how KV caching works, check out KV Caching Explained: Optimizing Transformer Inference Efficiency.
KV Cache Optimization Strategies for High-Performance Inference
KV caching is a fundamental technique for optimizing LLM inference workloads, especially as context lengths continue to grow. However, simply caching the KV data in GPU memory is often insufficient for handling the demands of large-scale, long-context workloads efficiently.
Like traditional caching systems, KV caching can benefit from additional optimization strategies to improve performance, reduce latency, and lower costs by offloading parts of the cache in GPU memory to other tiers, such as CPU memory, local or remote storage.
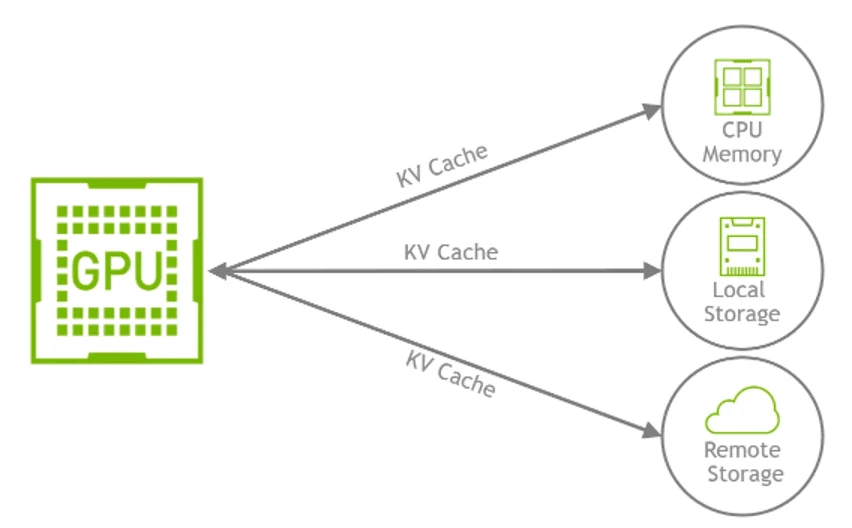
As of this writing there are few known optimizations strategies that can further extend basic KV caching and enable distributed large-scale serving systems:
- Cache Offloading – Move inactive KV cache segments from GPU memory to CPU or remote storage, freeing up GPU resources for active computations.
- Example: Offloading prefix caches for multi-turn conversations or long documents to CPU memory.
- Multi-Tier Offloading – Dynamically move KV caches among GPU, CPU, and remote GDS-backed storage based on access patterns and resource availability.
- Example: Keeping hot caches in GPU memory while offloading cold caches to Nutanix Files over GDS.
- Cross-Query Caching – Reuse KV cache segments across different queries that share common prefixes, reducing redundant computations and improving response times.
- Example: Multi-turn chat sessions or repeated document analysis with fixed preambles.
- Prefill–Decode (PD) Disaggregation – Separate prefill and decode stages onto different nodes, allowing for specialized resource allocation and improved throughput.
- Example: Large-scale deployments using separate GPU pools for prefill and decode operations
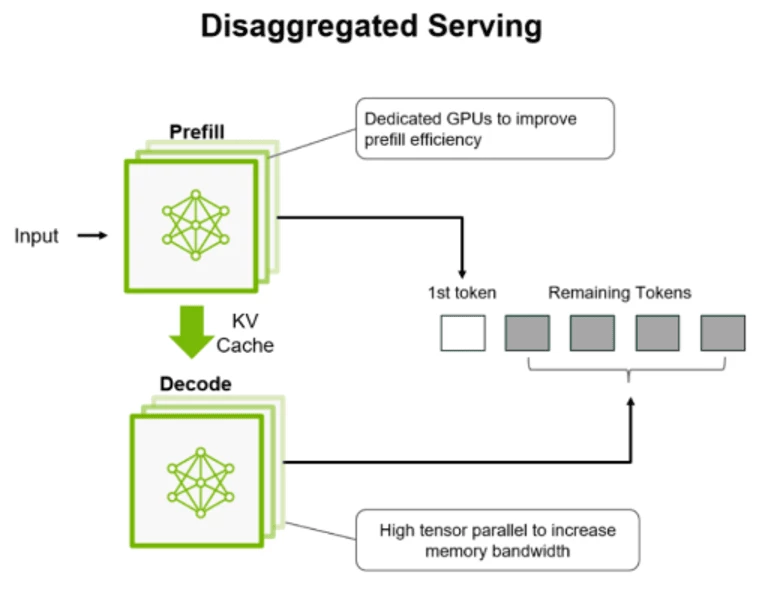
All optimizations depend on moving KV cache segments efficiently between GPU memory, CPU DRAM, NVMe storage, or remote storage tiers, such as Nutanix Files Storage over low-latency, high bandwidth data paths.
This is where the magic of LMCache combined with Nutanix Files Storage and NVIDIA GPUDirect Storage (GDS) provides the solution.
Conclusion
The expansion of context lengths in modern LLMs presents a significant challenge to efficient, scalable inference due to the resulting explosion in KV cache size. Simply adding more GPUs is unsustainable. Effective KV cache management—through strategies like offloading, multi-tier caching, and sharing—is the necessary paradigm shift. This intelligent software layer executes these strategies, but its success hinges on high-performance storage that can keep pace with GPU demands.
In the upcoming Part 2 of this series, we will dive deep into LMCache, an open-source KV cache management system designed to implement these advanced optimization strategies. We will detail how LMCache, when tightly integrated with Nutanix Files Storage and accelerated by NVIDIA GPUDirect Storage (GDS), creates a critical high-throughput, low-latency persistent storage foundation. This integration is essential for transforming LLM scalability and cost-efficiency by allowing for effective cross-query cache sharing, multi-tier offloading, and disaggregation of the prefill and decode stages.
References / Further Reading
- LMCache GitHub
- NVIDIA GPUDirect Storage
- Nutanix Files Product Page
- Nutanix Files Performance Profile for AI Workloads
- Nutanix Kubernetes Platform
- vLLM Project
- HackerNoon: Optimizing LLM Performance with LM Cache
- NVIDIA Dynamo Blog
- LLM Inference VRAM & GPU Requirement Calculator
- KV Caching Explained: Optimizing Transformer Inference Efficiency
©2026 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product and service names mentioned are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned are for identification purposes only and may be the trademarks of their respective holder(s). This content reflects an experiment in a test environment. Results, benefits, savings, or other outcomes described depend on a variety of factors including use case, individual requirements, and operating environments, and this publication should not be construed as a promise or obligation to deliver specific outcomes.