


本記事は2018年6月20日にJosh Odgers氏が投稿した記事の日本語版です。
Nutanixには、いくつもの非常に重要でユニークな自己修復機能があります。これらによって従来からのSAN/NAS装置だけでなく、他のHCI製品とも差別化されています。
Nutanixは、SSD/HDD/NVMeデバイスの損失やノードの障害を完全に自動で自己修復するだけでなく、ユーザーの介入なしに管理スタック(PRISM)を完全に復旧させることができます。
まず最初に、デバイスやノードの障害からデータを自己修復する方法について説明します。
従来のデュアルコントローラーのSANと、平均的*なサイズの8ノードのNutanixクラスターを単純に比較してみましょう。
*平均値は、全世界の顧客数を販売台数で割って算出しています。
1台のストレージコントローラが故障した場合、SAN/NASでは回復力が失われます。ベンダーがコンポーネントを交換し、回復力(多くの場合は性能劣化も)を取り戻すまでは、SLA(サービスレベルアグリーメント)を守るために奔走しなければなりません。
Nutanixと比較すると、8台のストレージコントローラのうち1台(12.5%)だけがオフラインになり、7台がワークロードへのサービスを継続し、回復力を自動的に取り戻すことができます(パート1で示したように、通常は分単位で回復します)。
以前、「ハードウェアサポート契約と24時間365日のオンサイトが不要な理由」というブログで、このコンセプトを詳しく紹介しました。簡単に言うと、プラットフォームの回復力を取り戻すために、新しい交換部品の到着や、さらに悪いことに人手に依存している場合、ハードウェアの交換やマニュアルでの作業なしに完全な回復力を持つ状態に自己回復できるプラットフォームに比べて、ダウンタイムやデータロスのリスクは飛躍的に高くなります。
「もっと小さな(Nutanixの)クラスターではどうか」と反論する人(あるいは競合他社)もいるかもしれません。
よくぞ聞いてくださいました。4ノードのクラスターであっても、ノード障害が発生すると、ハードウェアの交換やマニュアルでの作業なしに、完全に自己回復して回復力のある3ノードのクラスターになります。
Nutanix環境で、別のノード障害が発生してもダウンタイムなしに回復力のある状態に完全に自己修復できない唯一のシナリオは、3ノードクラスターです。しかし、3ノードクラスターでも、1つのノード障害を許容できます。データは再保護され、2つのノードだけでクラスターは機能し続けます。続けて障害が発生するとダウンタイムが発生しますが、致命的なデータ損失は発生しません。
重要なのは、2つのノードしか動作していないデグレード状態でも、ドライブの故障を許容できることです。
注:3ノードのvSANクラスターでノード障害が発生した場合、データは再保護されず、ノードが交換されて再構築が完了するまでリスクを抱えたままとなります。
Nutanixがデータ(および管理スタックであるPRISMも)の完全な自己修復を実行できる唯一の前提条件は、クラスタ内に十分な容量が存在することです。
どれくらいの容量が必要なのでしょうか? RF2構成ではN+1、RF3構成ではN+2の容量を推奨していますが、これは同時に2つの故障が発生した場合や、1つの故障の後に次の故障が発生した場合を想定しています。
そのため、最小サイズのクラスターの最悪のシナリオは、RF2では33%、5ノードのRF3クラスターでは40%となります。しかし、競合他社がFUD(Fear, Uncertainty and Doubt)を口にする前に、クラスタサイズが大きくなるにつれて自己修復に必要な容量がどの程度になるのかを見てみましょう。
次の表は、32ノードまでのクラスタサイズで、N+1およびN+2に基づいて、完全な自己修復に必要な容量の割合を示しています。
注:これらの値は、すべてのノードが100%の容量が使用されているという最悪のケースを想定しています。現実の世界ではオーバーヘッドは表に示されているよりも小さくなります。
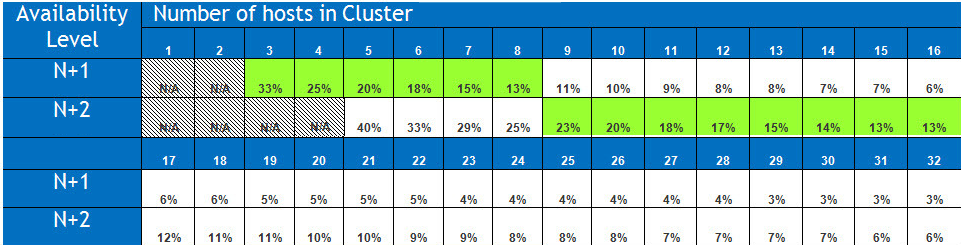
このように、平均的なサイズ(8ノード)のクラスターの場合、必要な空き容量はわずか13%(12.5%から切り上げ)です。
8ノードのクラスターをN+2とすると、2つのノードの故障を許容し、回復力のある状態に完全にリビルドするために必要な最大の空き容量は、わずか25%です。
NutanixのADSF(分散ストレージファブリック)のおかげで、Nutanixはクラスタ全体に均等に分散された1MBのエクステントを使用しているため、大規模なオブジェクト(例:256GB)を考慮する必要はありません。先進性を欠いたプラットフォームとは異なり、断片化による無駄なスペースは必要でないことに留意する必要があります。
注:クラスタ内のノードのサイズは、再構築に必要な容量には影響しません。
ADSFが他のプラットフォームに比べて優れている点は、Nutanixには「キャッシュドライブ」の概念や「ディスクグループ」の構成がないことです。
ディスクグループを使用することは、単一の「キャッシュ」ドライブの障害がディスクグループ(複数のドライブで構成される)全体をオフラインにし、必要以上に集中的な再構築動作を余儀なくされるため、耐障害性に対するリスクが高くなります。ADSFにおける単一のドライブ障害は、まさに単一のドライブ障害であり、そのドライブ上のデータのみを再構築する必要があります。もちろん、効率的な分散方法で行われます(すなわち、他の製品のような「1対1」ではなく「多対多」の操作です)。
Nutanixでシングルドライブの障害が問題になるのは、ノード障害に相当するシングルSSDのシステムの場合だけですが、明確に言うと、これはADSFの制限ではなく、選択されたハードウェア仕様の制限です。
本番環境では、シングルSSDのシステムの使用はお勧めしません。デュアルSSDシステムの最小限の追加コストよりも耐障害性の利点の方が大きいからです。
興味深い点は、vSANは間違いなく常にシングルシステムであるということです。「ディスクグループ」には「キャッシュドライブ」が一つしかないため、単一障害点となるためです。
クラスタが自己修復した後、別の障害が発生したらどうするのかという質問をよく受けます。私がNutanixで働き始めた2013年に、vForum Sydneyでセッションを行い、このトピックを詳しく説明しました。このセッションは立ち見が出るほどの盛況ぶりで、私は次のようなブログ記事を書きました。この記事では、5ノードのクラスターが障害から自己回復して完全に回復力のある4ノードのクラスターになり、さらに別の障害に耐えて3ノードのクラスターに自己回復する様子を紹介しています。
この機能は今に始まったことではなく、新しいプラットフォームと比較しても、市場で最も耐障害性の高いアーキテクチャと言えます。
今週のvForum Sydenyで私は「コンバージドインフラストラクチャでvSphereを新たなレベルへ」というプレゼンテーションを実施しました。まず、セッションに参加してくださった皆様に御礼申し上げます、大変盛況で、Q&Aでは多くの・・・
「ディスクグループ」のような構成要素の障害を許容する必要がある場合、障害に備えて確保しなければならない空き領域の量は、最近のVMware vSANの記事「vSan degraded device handling」から分かるように、はるかに多くなります。
この記事から考察すべき重要な引用は2つあります。
クラスタに25~30%の空き容量を確保することを強くお勧めします。
ドライブがキャッシュデバイスの場合、ディスクグループ全体がオフラインになります。
vSANアーキテクチャの欠陥を考慮すると、VMware社がFTT2(3つのデータコピー)に加えて25~30%の空き容量を推奨している理由がわかります。
次に、ノード障害からの管理スタックの自己修復について説明します。
設定、管理、監視、拡張、自動化に必要なすべてのコンポーネントは、クラスター内のすべてのノードに完全に分散されています。vSAN/ESXiがvCenterを必要とするのとは異なり、コア機能のためにお客様が管理コンポーネントを導入する必要はありません。
また、 こちらもvSAN/ESXiとは異なり、ユーザーが管理スタックの高可用性を構成する必要はありません。
その結果、Nutanix/Acropolisの管理レイヤーには単一障害点が存在しません。
典型的な4ノードのクラスターを見てみましょう。
下図では、それぞれ1つのノードにサービスを提供する4つのコントローラVM(CVM)があります。このクラスタには、Acropolis Masterと複数のAcropolis Slaveインスタンスがあります。
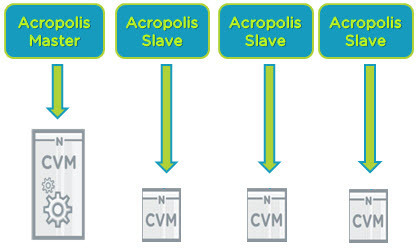
何らかの理由でAcropolis Masterが利用できなくなった場合、投票アルゴリズムによる選挙が行われ、Acropolis Slaveの1つがMasterに昇格します。
これは、Acropolisのデータが、ADFS(Acropolis分散ストレージファブリック)で保護された完全分散型のCassandraデータベースに保存されているからです。
クラスターにNutanixノードが追加されると、Acropolis Slaveも追加されます。これにより、クラスターを管理する作業負荷が分散されます。そのため、管理が問題になることはありません。
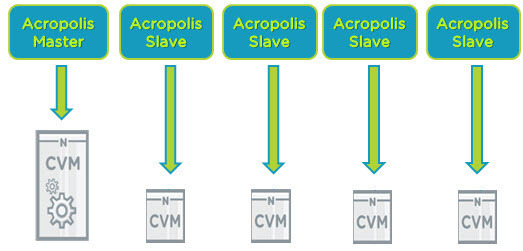
パフォーマンスの監視、統計データの収集、仮想マシンコンソールのプロキシ接続などは、マスターとスレーブのインスタンスが提供する管理タスクのほんの一部です。
Nutanixのもう一つの利点は、管理層のサイズやスケールを手動で調整する必要がないことです。仮想アプライアンス、データベースサーバ、Windowsインスタンスの導入、インストール、設定、管理、ライセンスが不要なため、コスト削減と環境の管理が容易になります。
キーポイント :
- Nutanix Acropolisの管理スタックは、クラスタにノードが追加されると自動的に拡張が行われるため、一貫性、回復力、パフォーマンスが向上し、管理性に影響を与える可能性のあるアーキテクチャ(サイジング)エラーの可能性を排除することができます。
私が競合他社の製品を紹介する理由は、特にデータ層と管理層の両方における耐障害性などの重要な要素について、お客様に根本的な違いを理解していただくことが重要だからです。
まとめ:
Nutanix ADSFは、データプレーンと管理プレーンの両方において、ハードウェアの交換を必要としない優れた自己修復の機能を備えております。そのために必要なキャパシティオーバーヘッドは最低限にとどめています。
もしベンダーが以下のような発言をしたら(すべてvSANに当てはまります)、会話は唐突に終了するでしょう。
- 1台のSSDが単一障害点となります。複数のドライブが同時にオフラインになり、すべてのデータを再構築する必要があります
- クラスター内に25~30%の空きスペースを確保することを強く推奨します
- リビルドは1対1の時間のかかるオペレーションです。場合によっては60分経たないと開始しません。
- 3ノードのvSANクラスターでノード障害が発生した場合、データは再保護されず、ノードが交換されて再構築が完了するまでリスクが残ります。
HCI製品を選ぶ際には、データ層と管理層の両方に自己修復機能があるかどうかを考慮してください。両方がインフラストラクチャーの回復力のために決定的に重要です。ダウンタイムのリスクが、ハードウェアの交換が迅速に行われるかどうかに依存するような状況に、ご自身を追い込むことはやめましょう。
私たちは皆、部品が入手できないためにベンダーのハードウェア交換のSLAが達成できなかったという恐ろしい話を経験したり、少なくとも耳にしたりしています。ですから、賢くありましょう。完全に自己修復することでリスクを最小化するプラットフォームを選択してください。