


本記事は2018年11月22日にJosh Odgers氏が投稿した記事の翻訳版です。
このシリーズでは、Nutanixプラットフォームがいかに優れた回復力を有しているかを示す幅広いトピックを取り上げてきました。これには、障害時であっても新規書き込みのためのデータ整合性を維持できることや、障害後に問題を引き起こす次の障害のリスクを最小限にするために、タイムリーにリビルドする能力が含まれます。
このような情報があるにもかかわらず、競合ベンダーは、「2つのコピーが失われてしまえば、リビルド時間は問題の本質ではない」といった主張で、Nutanixが提供するデータインテグリティ(データ整合性・一貫性の担保の仕組み)の信用を貶めようとしています。現実的には、データの両方のコピーが同時に失われる可能性は低く、これは安易な主張です。しかし、もちろんNutanixは、最大限の回復力を求めるお客様のために、3つのデータのコピーを保存可能なRF3もサポートしています。
それでは、パート10に進みましょう。ここでは、ディスクスクラビングとチェックサムという2つの重要なトピックについて説明します。この2つの重要なトピックは、RF2とRF3の構成が非常に高い回復力を持ち、データが失われる可能性が極めて低いことを保証するものです。
まず、チェックサムについてですが、チェックサムとは何でしょうか?チェックサムは、書き込み操作中に作成された少量のデータであり、後で(チェックサムのデータを)読み込んで、実際のデータが完全なままであるかどうか(つまり、破損していないかどうか)を確認できます。
次に、ディスクスクラビングですが、データの整合性を定期的にチェックするバックグラウンドタスクであり、エラーが検出された場合、ディスクスクラビングはエラー修正プロセスを開始して、修正可能な単独のエラーを修正します。
Nutanixは、すべての書き込み操作(RF2またはRF3)に対してチェックサムを実行し、すべての読み取り操作に対してチェックサムを検証します。これは、データの整合性検証がIO処理の一部であり、スキップしたりオフにしたりすることができないことを意味します。
データの整合性は、あらゆるストレージプラットフォームの最優先事項であり、これが故にNutanixはチェックサムをオフにするオプションを提供していません。
Nutanixは読み込み時にチェックサムを実行するので、アクセスされるデータは常にチェックされていることになります。また、何らかの形で破損が発生した場合、Nutanix AOSは自動的にRFコピーからデータを取得してIOをサービスし、同時にエラー/破損を修正して、その後に障害が生じた場合でも、データ損失を引き起こさないようにします。
また、Nutanixがノード/ディスクドライブまたはエクステント(Nutanixにおいて1MB単位で管理されるデータブロック)の障害からデータをリビルドする速度は、データの整合性を維持し続ける上でも非常に重要です。
しかし、コールドデータについてはどうでしょうか?
多くの環境には大量のコールドデータがあり、これらのデータは頻繁にアクセスされていないことを意味します。したがって、データがアクセスされていない場合、読み取り操作のチェックサム機構では、そのデータはこまめにチェックされることはありません。このようなデータを保護するにはどうすればよいでしょうか。
答えは簡単です、ディスクスクラビングです。
フロントエンドの読み取り(例:VM/アプリからの読み取り)操作でアクセスされていないデータに対しては、Nutanixのディスクスクラビング機構によって、1日1回コールドデータがチェックされます。
スクラビングのタスクはクラスター内のすべてのディスクドライブで同時に実行されています。そのため(常にデータの整合性を担保していることから)、RF2(データの2つのコピー)を使用しているシナリオで、単独ドライブの障害と、エクステント(データの1MBのブロック)が破損し、同じデータを保持した2台のディスクドライブが同時に故障したりするような、複数の同時障害が発生する可能性は、限りなく低くなります。
このような障害は、過去24時間以内にそのエクステントで読み取り操作が行われておらず、2つのデータのコピーにおいてバックグラウンドでのディスクスクラビングも実行されておらず、さらにNutanix AOSのディスクドライブ障害の予兆検知機能がドライブの劣化を検出しておらず、加えてデータを積極的に再保護(データのリビルド)している最中のような、完璧なタイミングでない限り発生しません。
仮にこのシナリオを発生させようとすると、例えば、ディスクドライブに障害が発生し、かつ故障したディスクドライブと同一のデータを格納しているエクステントのデータブロックが破損している必要があります。NX3460のような小規模な4ノードクラスタであっても、24台ものドライブがあるため、その確率は極めて低くなります。クラスターが大きければ大きいほど、このようなシナリオの可能性はさらに低くなり、また、これまでのシリーズで学んだように、クラスターのリビルド性能も高速化します。
それでもリスクに対する強い懸念や、これらのイベントがすべて完璧に揃う可能性を強く想定する場合にはRF3を導入し、3つの同時障害に加えてすべてのイベントが揃わなければデータ損失が生じ得ないようなリスクに備えます。
VSANを導入されている環境の場合、ディスクスクラビングは年に1回しか行われません。さらにVMware社はチェックサムをオフにすることを頻繁に推奨しており、その中には、私がこのままでは、お客様がデータ損失の高い不必要なリスクに晒されると考え、指摘を行った後に更新されたSAP HANAのドキュメントも含まれています。
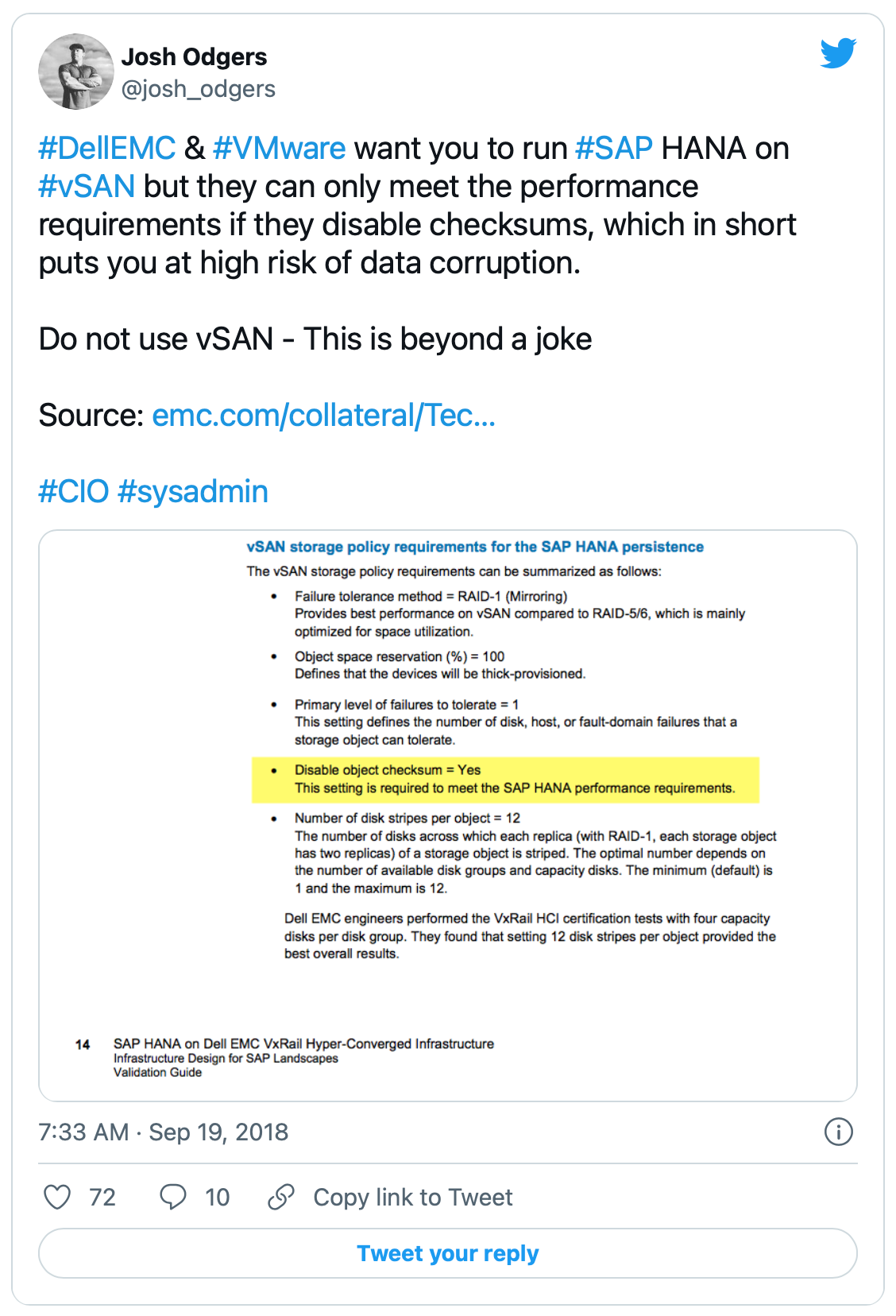
#DellEMC と #VMware は #vSAN 上で #SAP HANA を動作させることを検討する際に、チェックサムを無効にしなければパフォーマンス要件を満たすことができず、結果的にデータ破損のリスクが高くなります。
vSAN を使用しないでください - これは冗談では済まされません。
ソース:https://www.emc.com/collateral/TechnicalDocument/dell-emc-vxrail-hyper-converged-infrastructure-validation-guide.pdf
※Joshの指摘当時、VxRAIL/vSANのドキュメントでは、単純な記載ミスではなく、明示的にSAP HANAの性能要件を満たすためチェックサムはオフを推奨していたが、Joshの指摘後にチェックサムのオン設定を推奨するようにドキュメントが更新されている
Nutanixには、バックグラウンドのディスクスクラビングアクティビティを監視する機能もあります。以下のスクリーンショットは、ディスク#126のスキャン統計を示しています。この環境では、2TBのSATAドライブが約75%の使用率で使用されています。
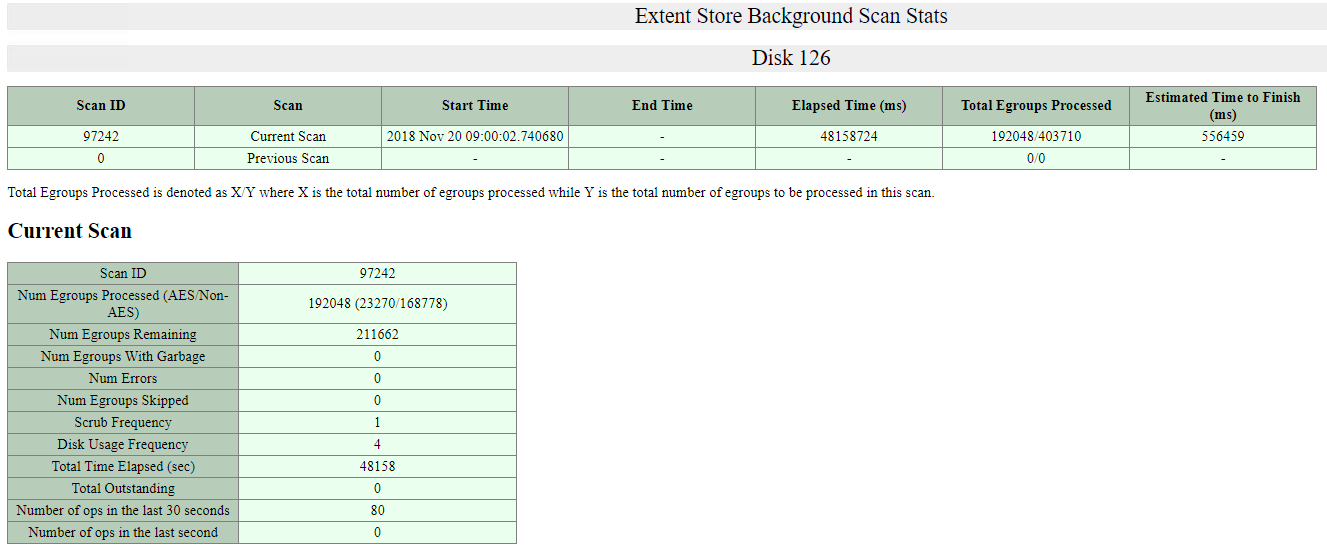

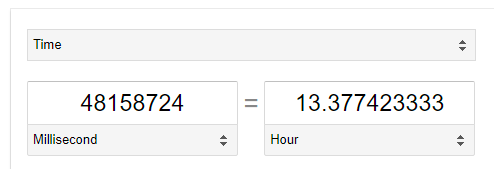
AOSは、ディスクのサイズに関わらず、ディスク全体のスクラビングが24時間ごとに終了することを保証する速度でディスクのスクラブを実行します。上のスクリーンショットでは、このスキャンは既に48158724ミリ秒(googleによると約13.3時間)にわたって実行されており、完了までの残り時間は556459ミリ秒(約0.15時間)となっています。
データが容量と性能に基づいて動的に均等に分散されるAcropolis Distributed Storage Fabric(ADSF)の分散型の特性と、ノードごとに複数のドライブが同時に故障しても耐えられるクラスターの能力、すべての読み書き操作で実行されるチェックサム、毎日実行されるディスクスクラビング、さらにHDDやSSDをプロアクティブに監視し、これらディスクドライブが故障する前にデータの再保護(データのリビルド)を行います。
さらにADSFが故障後にデータをリビルドするスピードも速いことから、レジリエンシーファクター2(RF2)を使用しても優れた回復力が得られる理由が容易に理解できます。
それでもまだ満足できない場合は、レジリエンシーファクターを3(RF3)に変更すると、さらに、もう1段高い保護のレイヤーが設けられ、RF3を有効化したワークロードに対する保護がさらに強化されることになります。
レジリエンシーファクター(vSANの用語でFailures to Tolerate)を検討する際に、NutanixとvSAN上の2つのデータのコピーが同等であると考えてはいけません。NutanixのRF2は、vSAN上のFTT1(2つのコピー)よりもはるかに回復力が高く、VMwareは頻繁にFTT2(3つのデータコピー)を推奨しています。実際にこれは、以下の理由に起因しています。
- vSAN は分散型ストレージ ファブリックではない
- vSAN のリビルドパフォーマンスは遅く、影響が大きい
- vSANのディスクスクラビングは年に1回しか行われない
- VMwareはチェックサムをオフにすることを頻繁に推奨している(!!!)
- 1台のキャッシュドライブが故障すると、ディスクグループ全体がオフラインになる
- オールフラッシュのvSAN環境で圧縮や重複排除を使用している場合、1台のドライブ故障でディスクグループ全体がダウンする
アーキテクチャは重要です。HCIやストレージ製品のマーケティングスライドを超えて時間をかけて調査すれば、特にスケーラビリティ、回復力、データインテグリティに関しては、Nutanix ADSFが明らかにリーダーであることがわかります。
他の企業や製品は、市場調査ではリーダーと謳っていますが(率直に言って、インカーネルが有利だとか、10:1デデュープだとかは、(Bullshit)でたらめで)、Nutanixは、実際のビジネス成果をもたらす強固なアーキテクチャで、重要な点でリードしています。